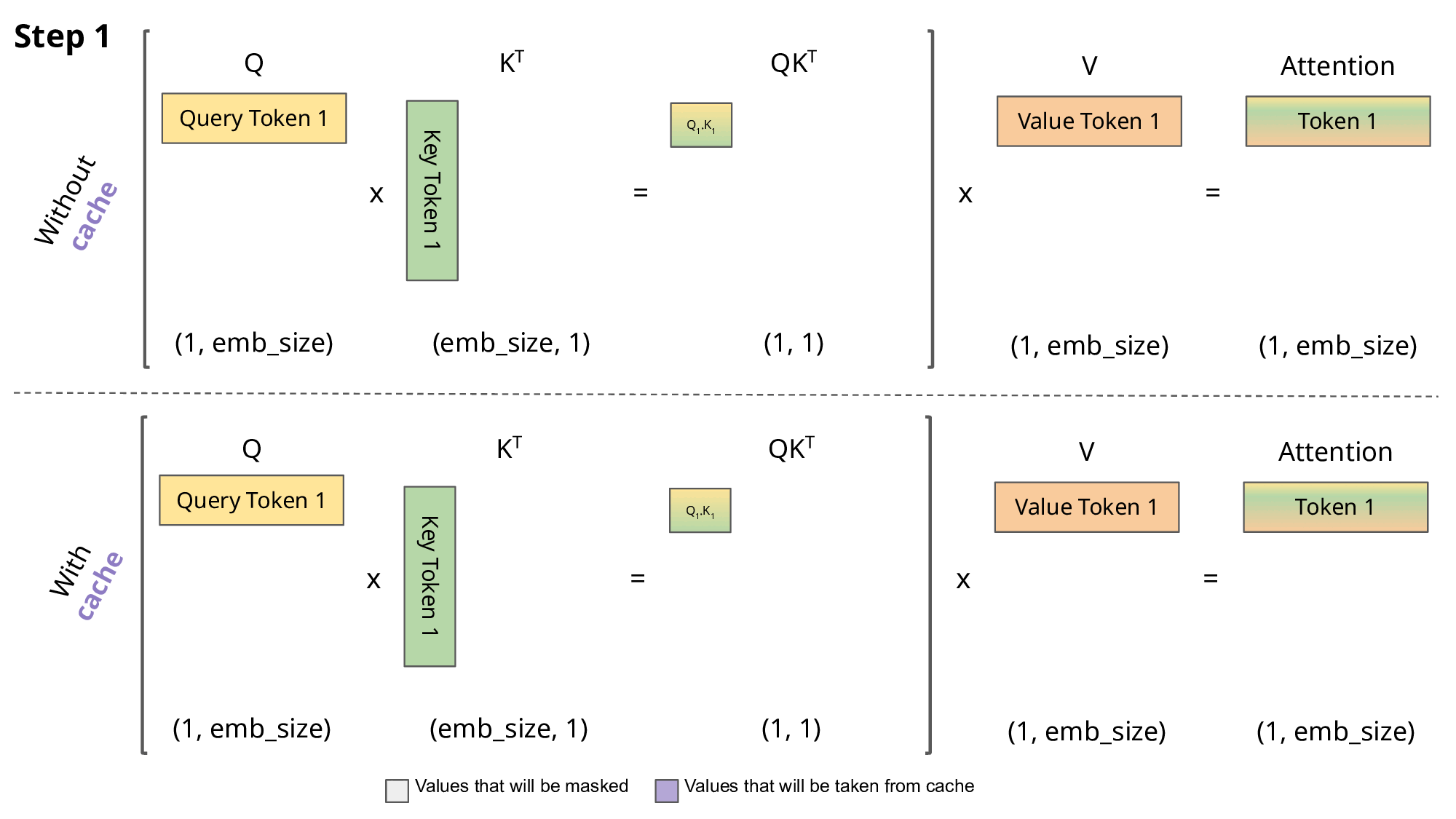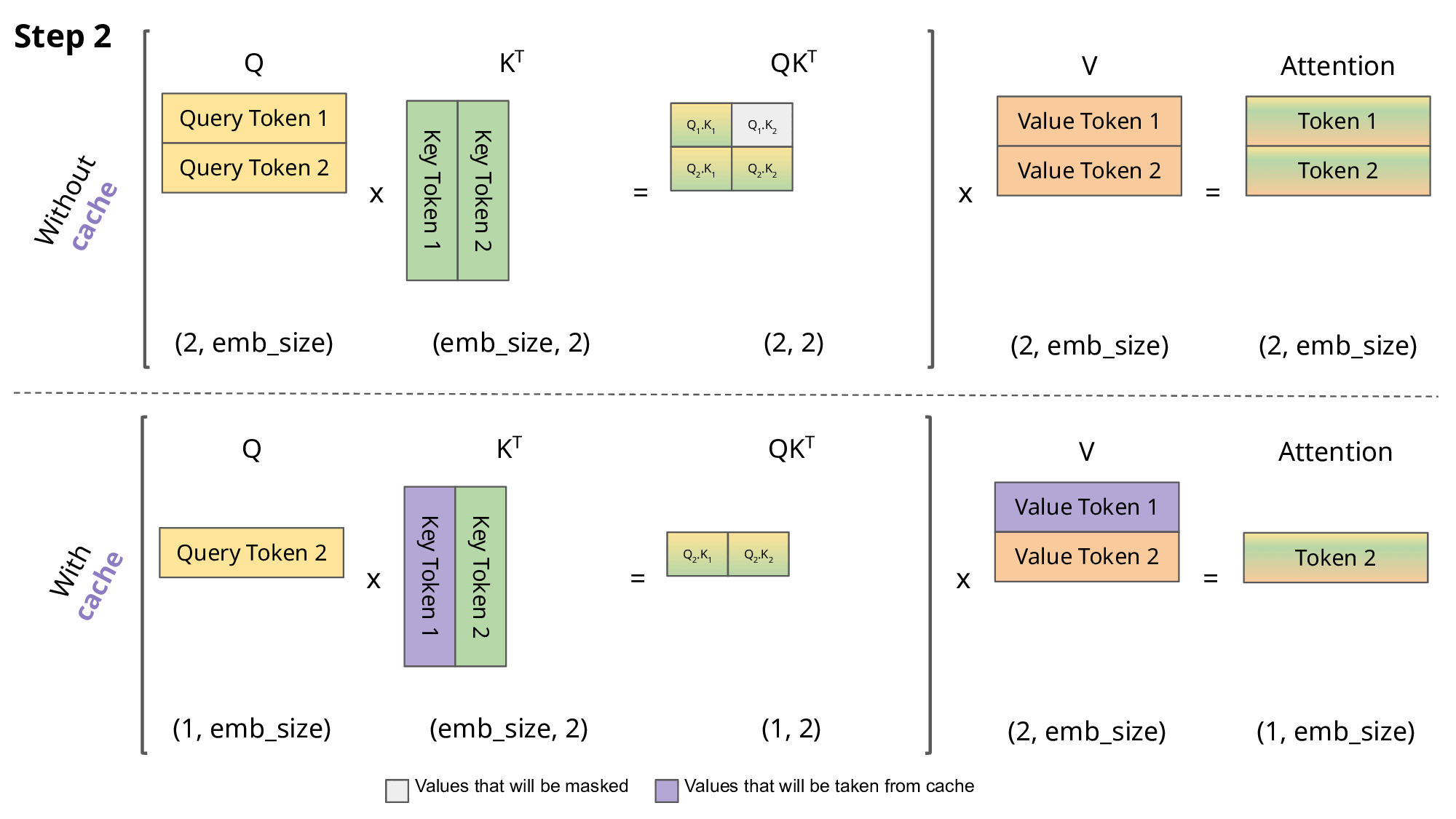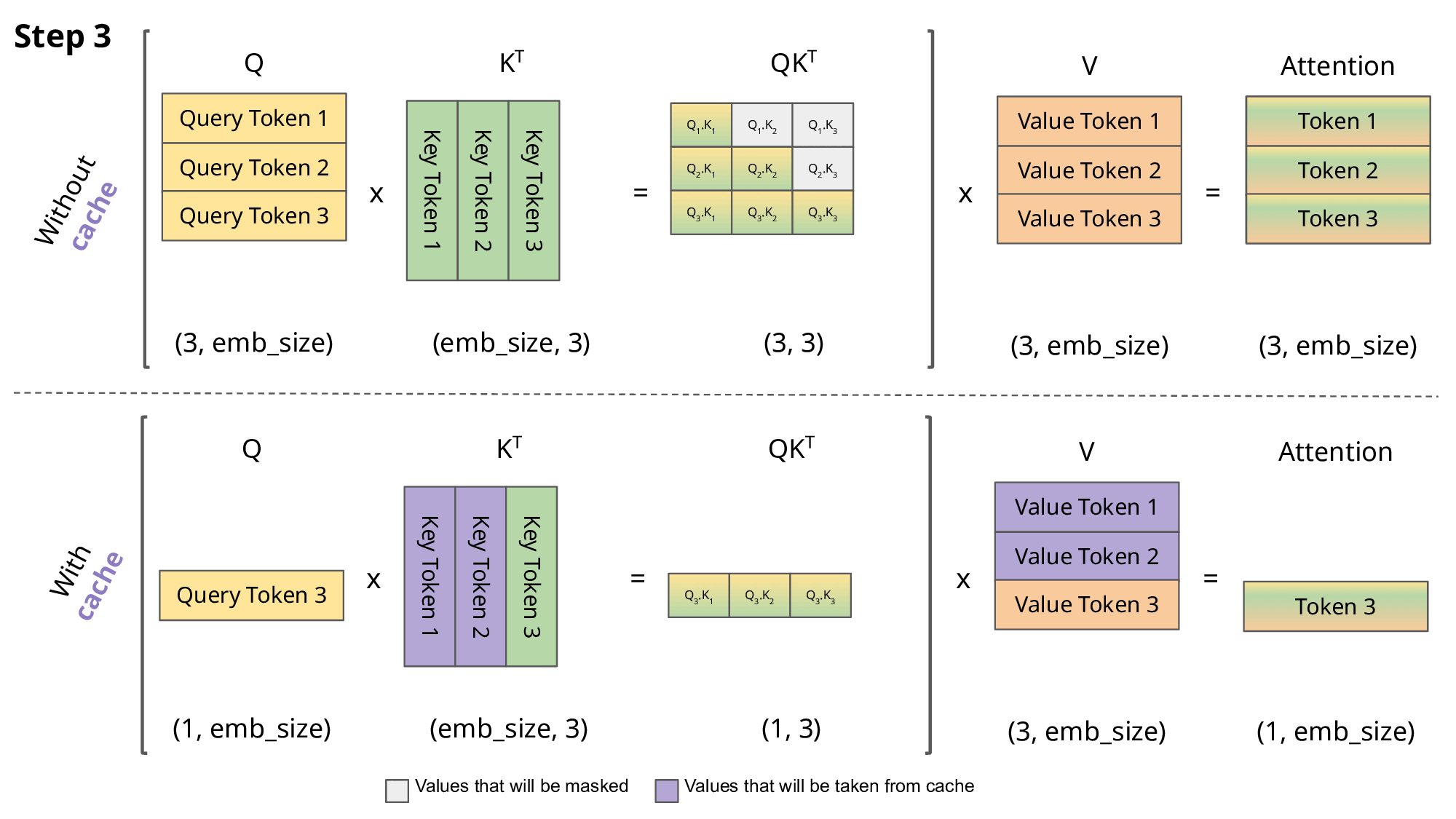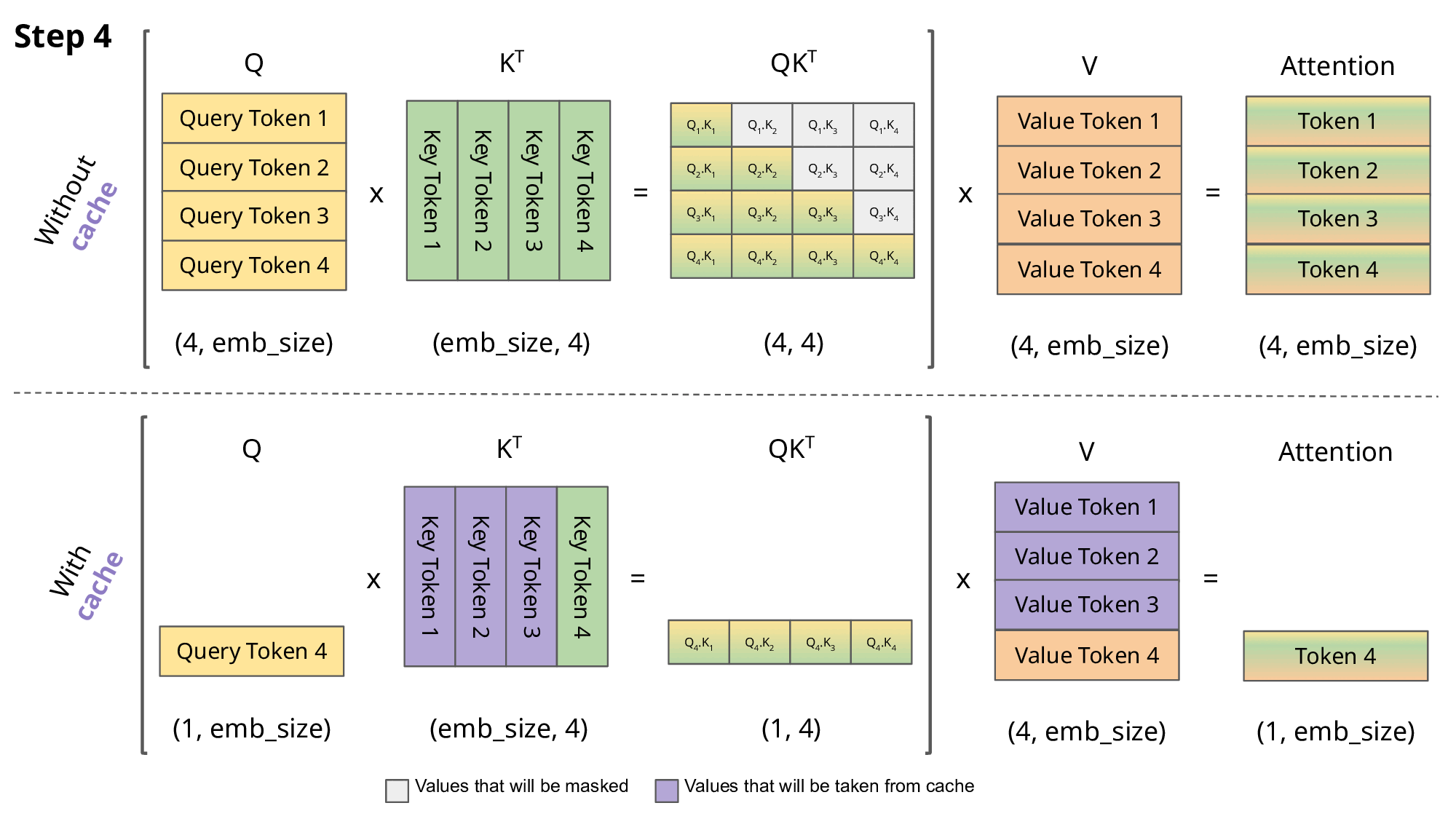
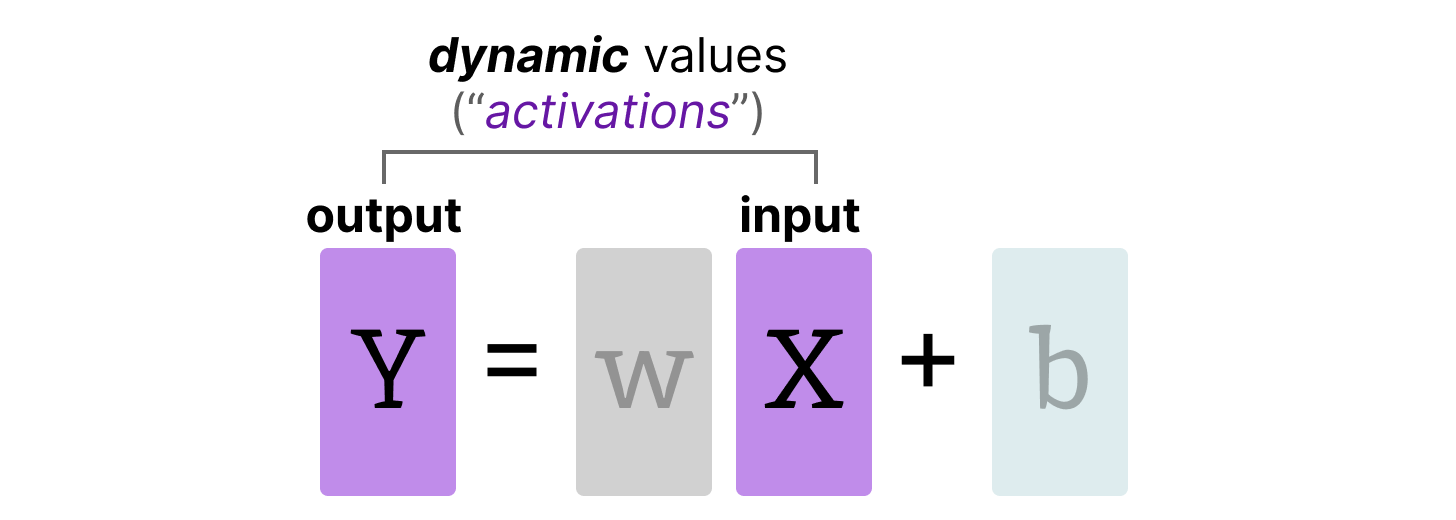
Showing 120 of 120on this page. Filters & sort apply to loaded results; URL updates for sharing.120 of 120 on this page
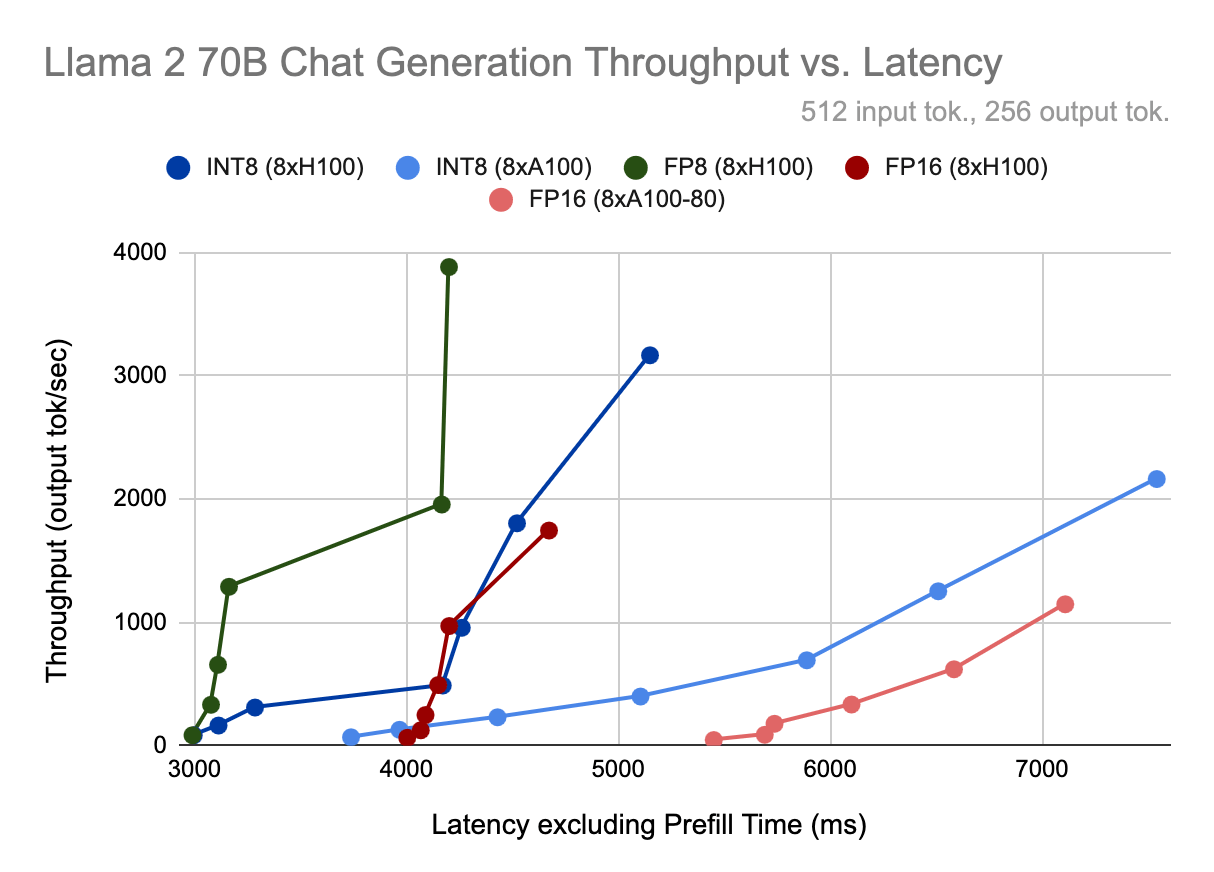
Rethinking AI TCO: Why Cost per Token Is the Only Metric That Matters
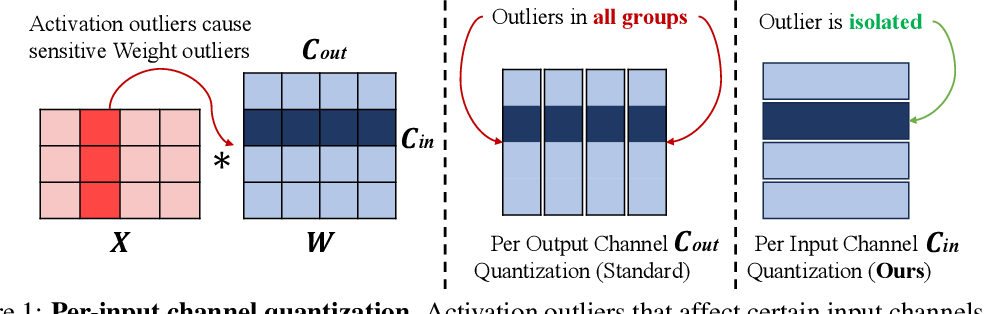
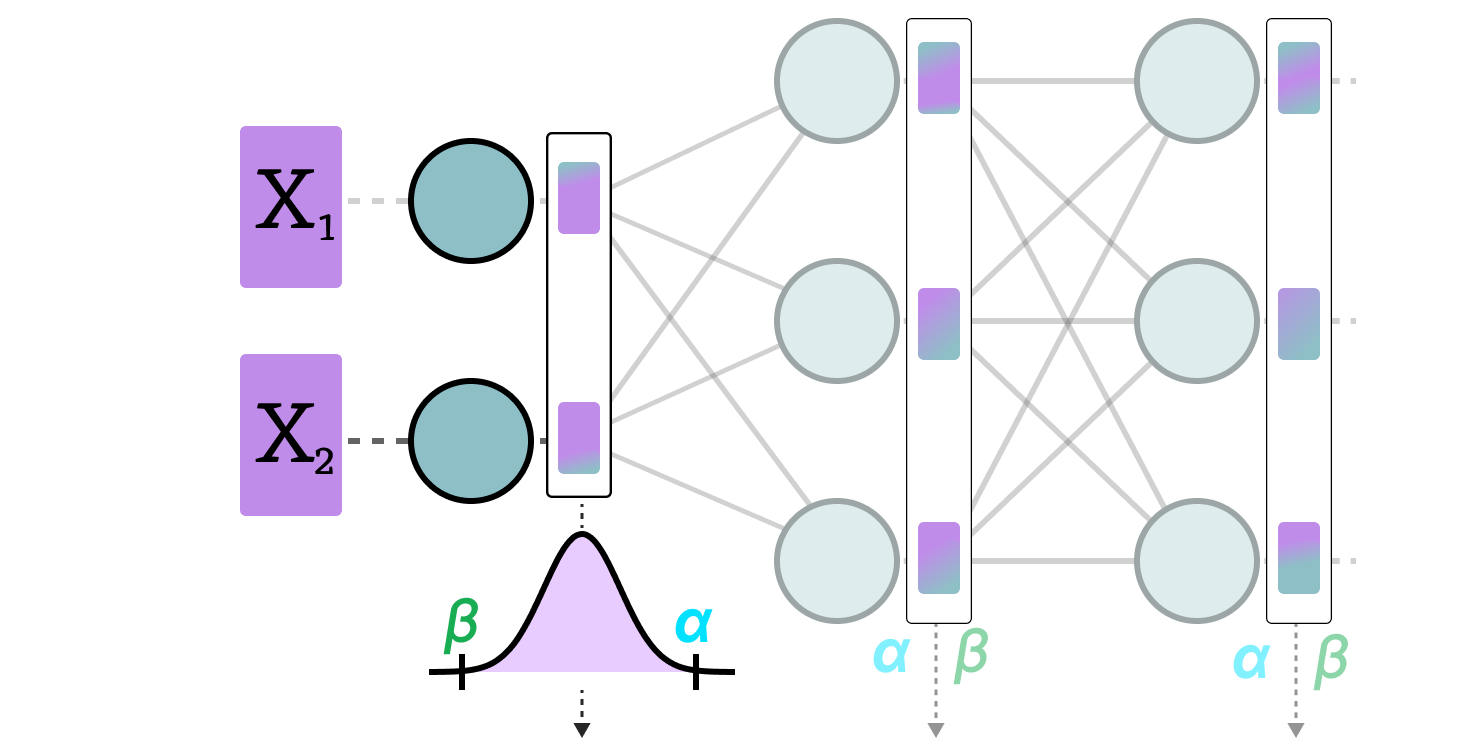
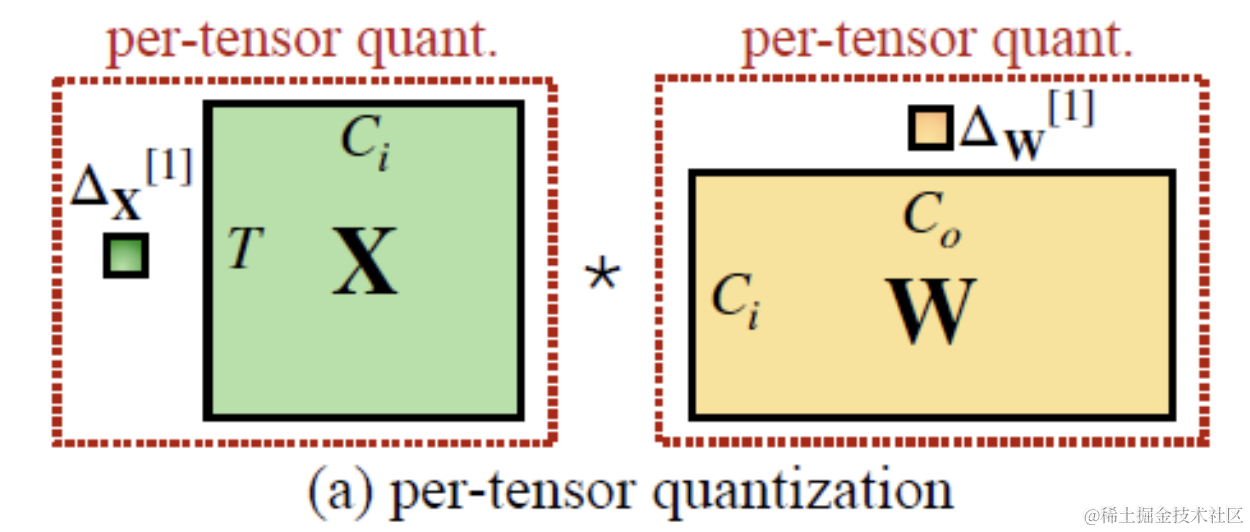
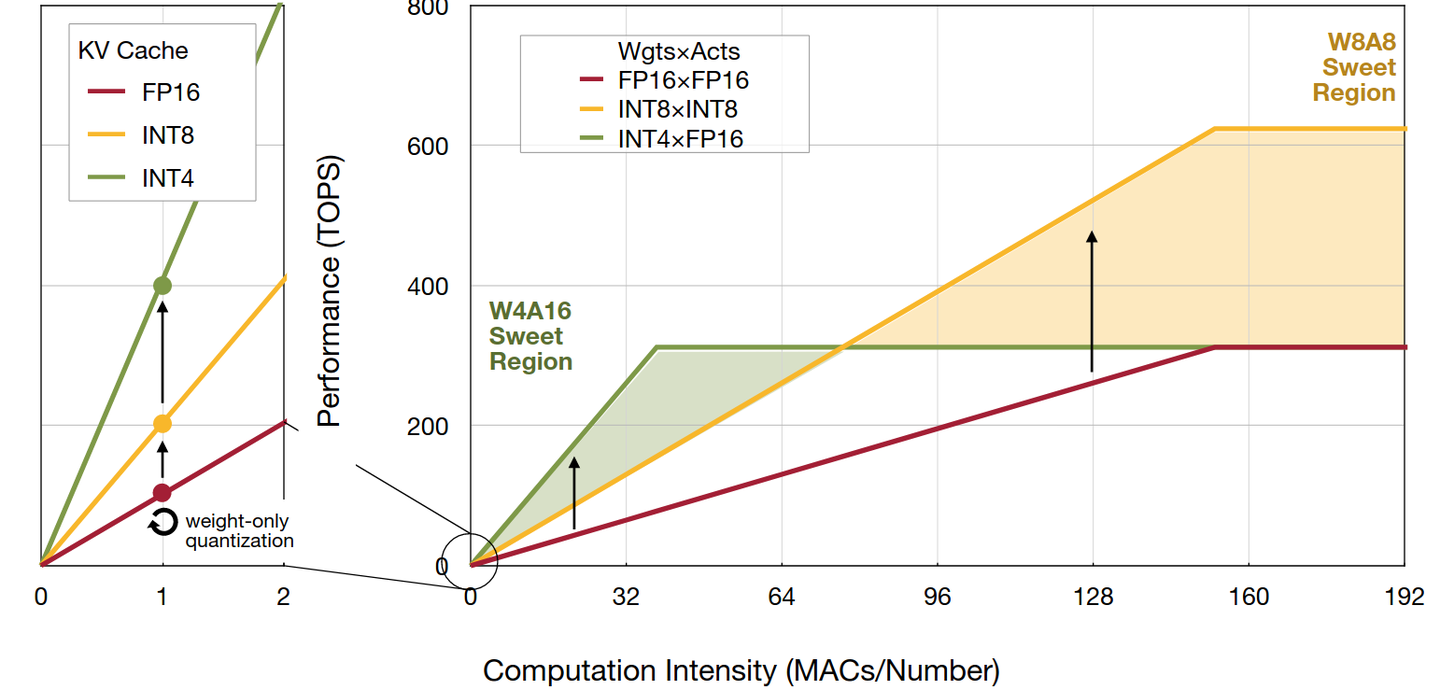
Figure 1 from Intuition : perIC quantization Per Output Channel ...
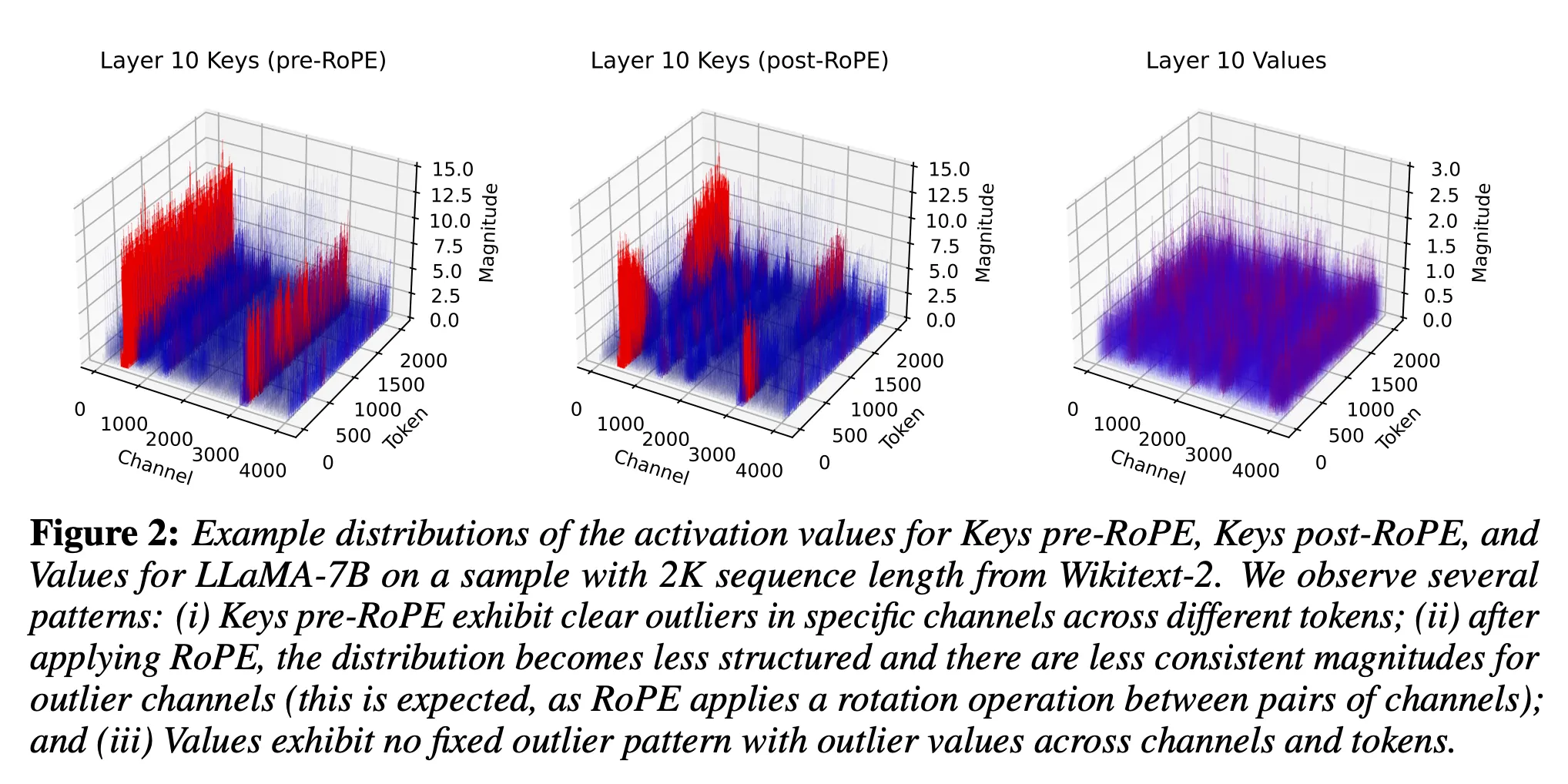
Contribution to the next token prediction per head on repeated ...
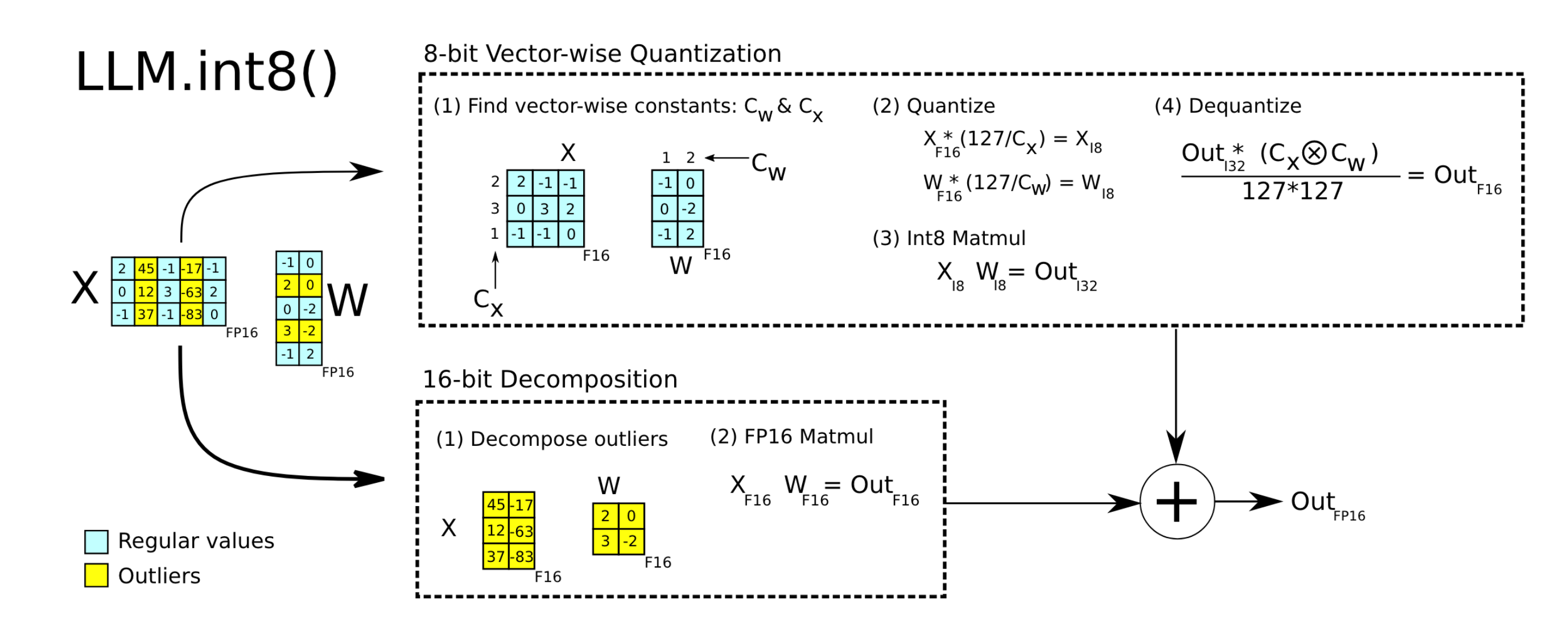
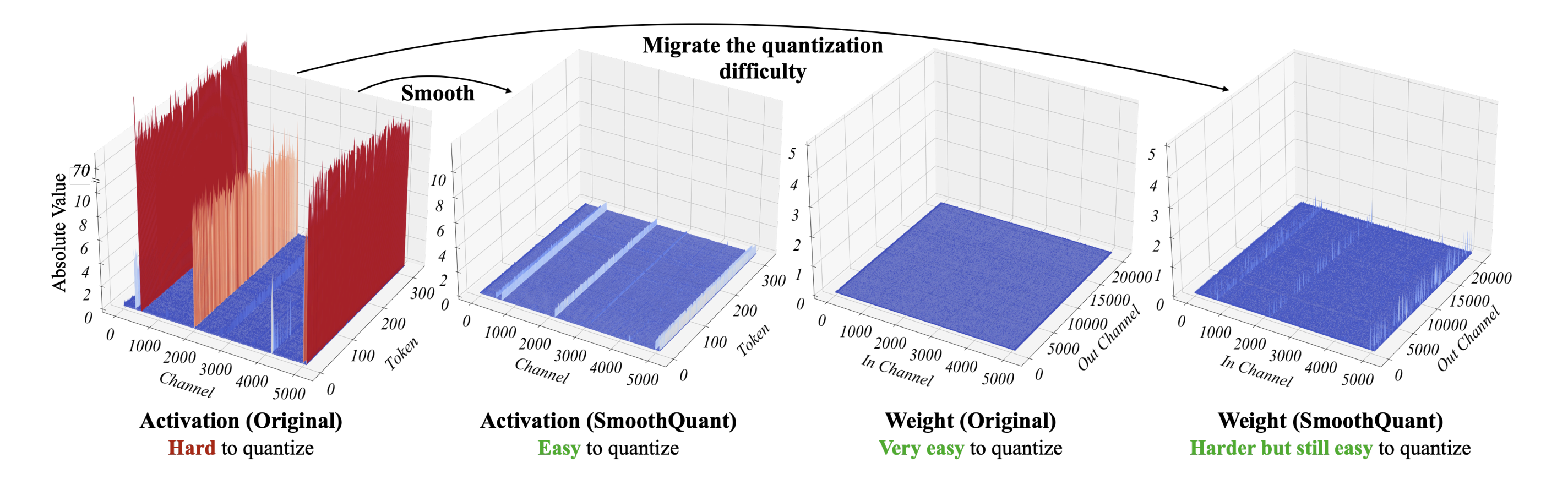
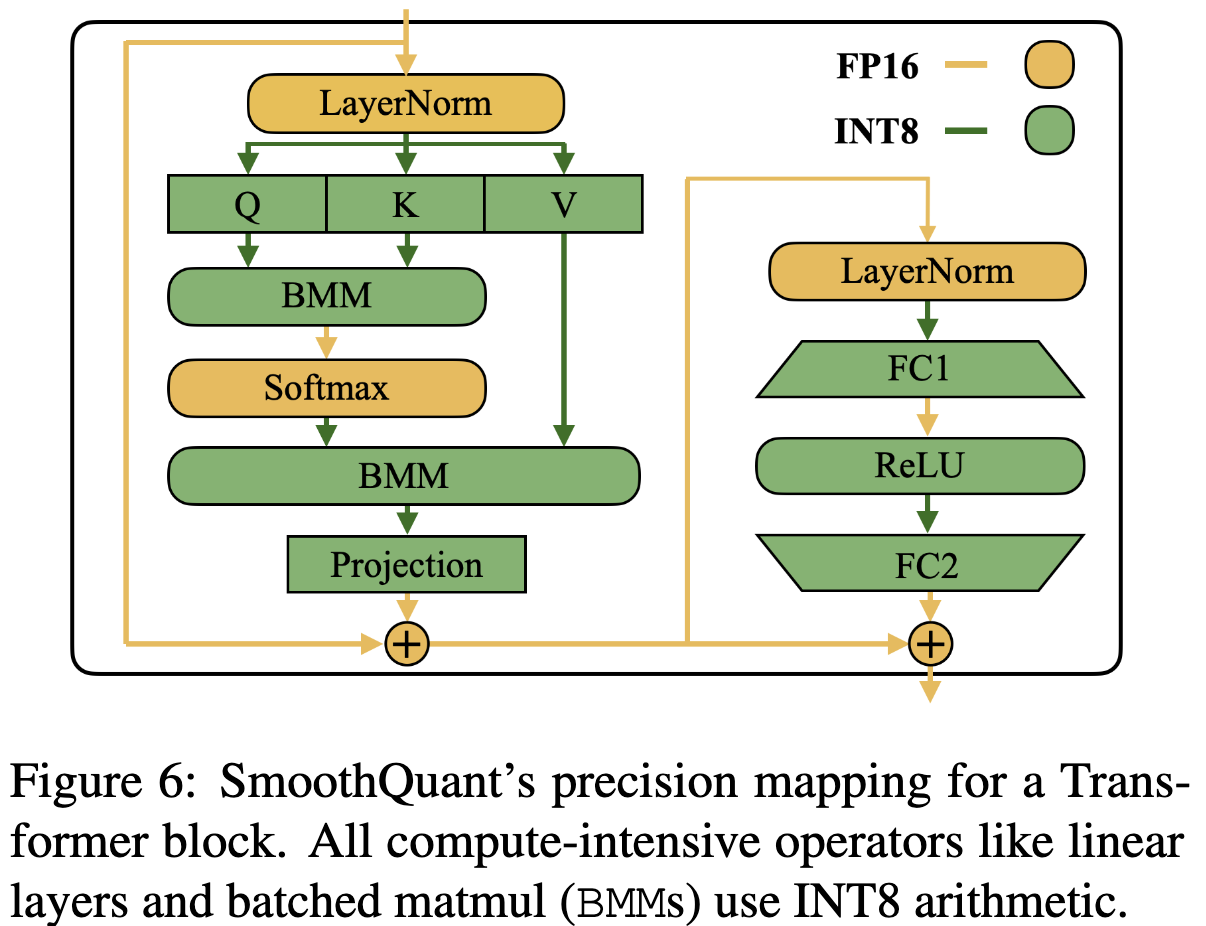
SmoothQuant: Accurate and Efficient Post-Training Quantization for ...
Edge-ASR: Towards Low-Bit Quantization of Automatic Speech Recognition ...
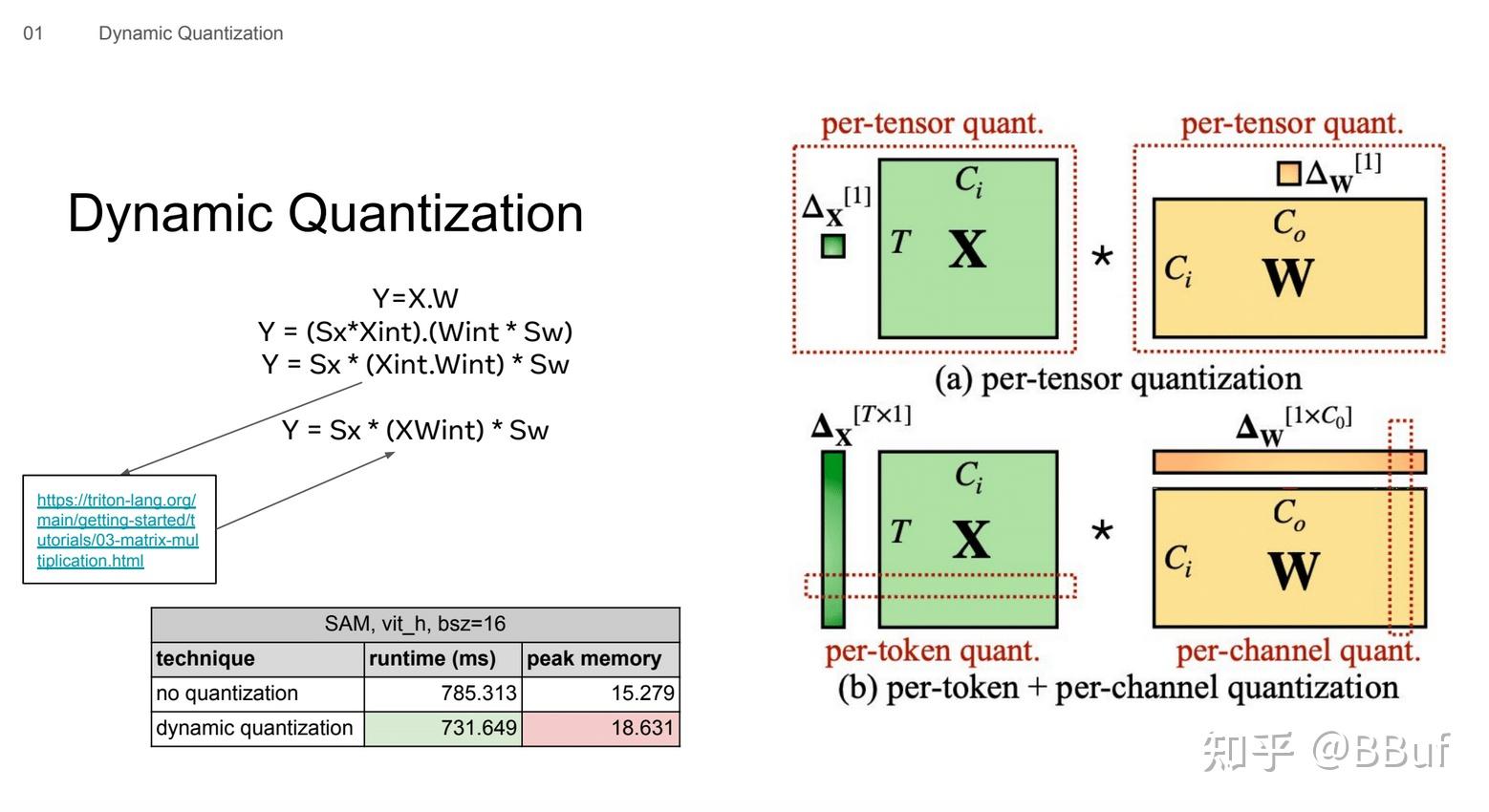
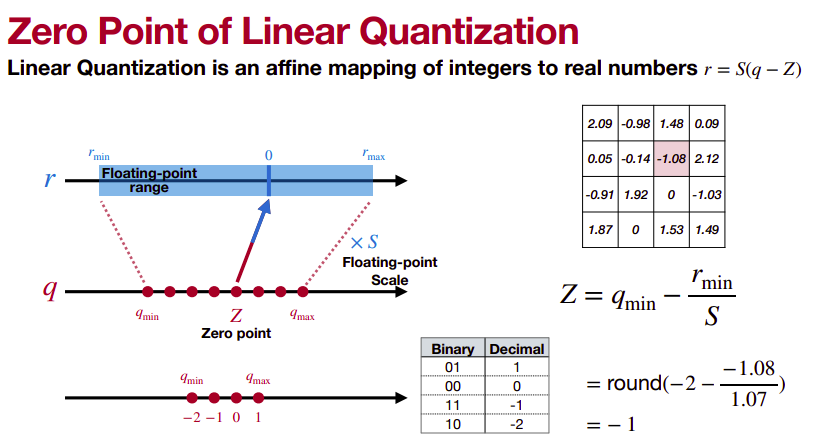
Quantization 1/2 - Seunghyun Oh
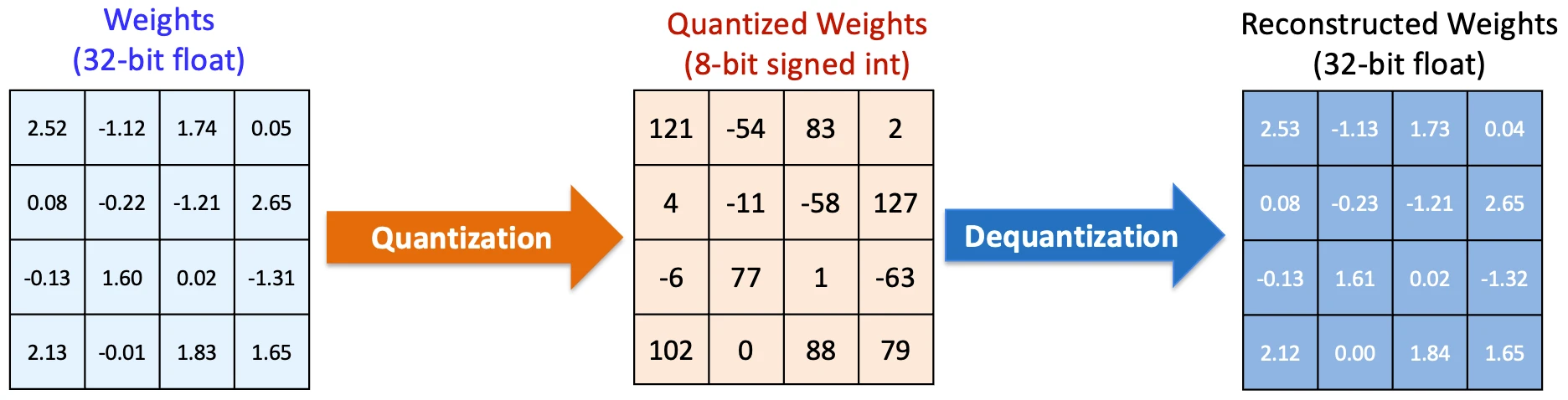
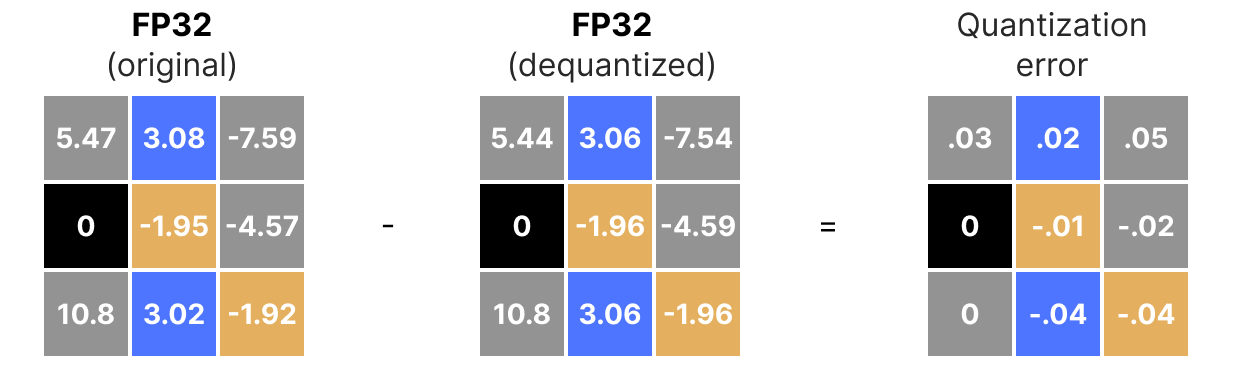
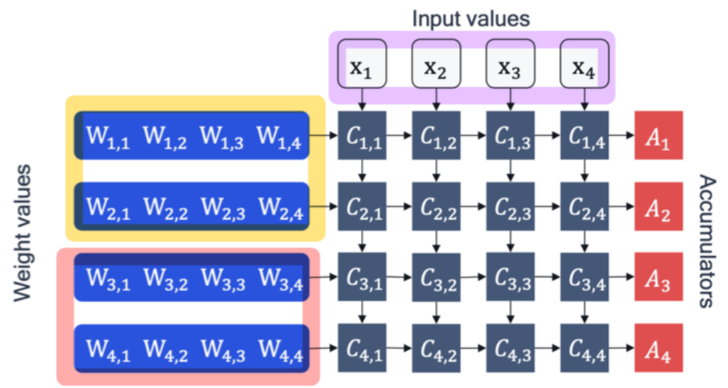
How Quantization Works: From a Matrix Multiplication Perspective ...
Understanding Quantization in Large Language Models | by ...
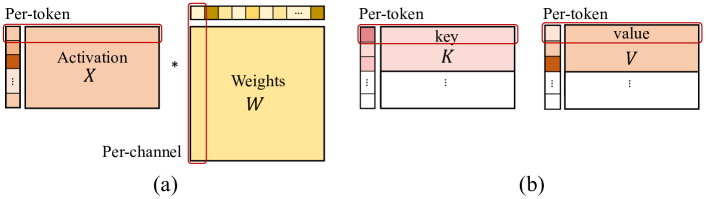
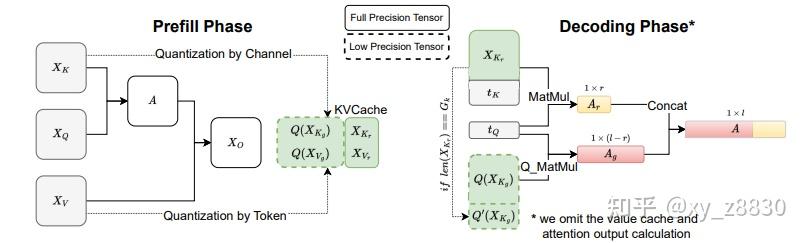
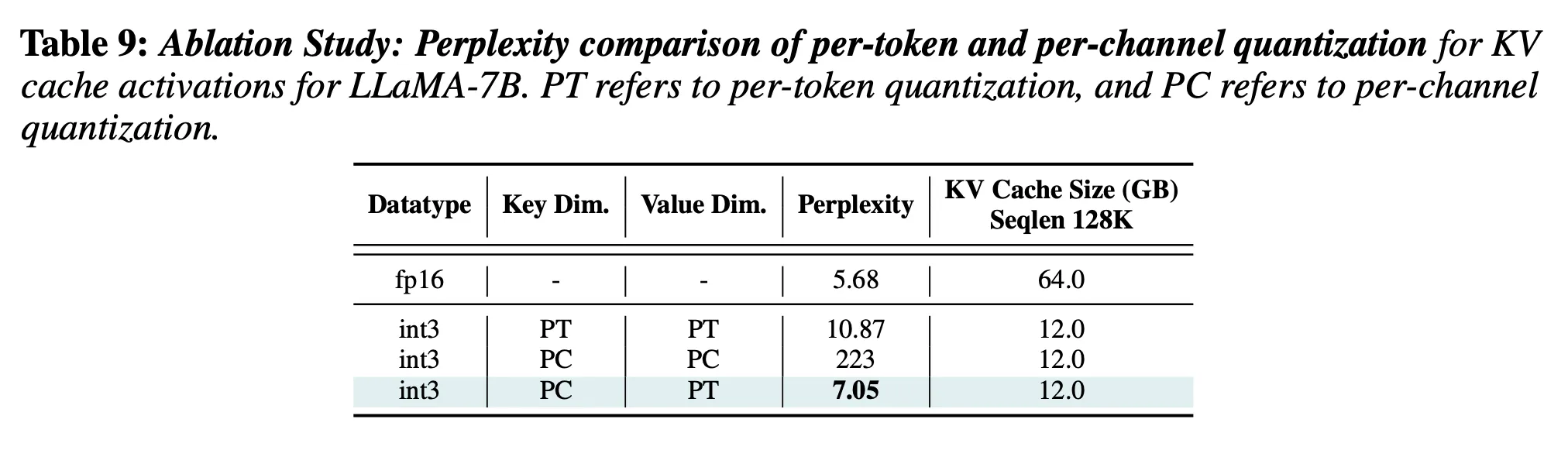
[Paper review] KIVI: A Tuning-Free Asymmetric 2bit Quantization for KV ...
CUDA-MODE课程笔记 第7课: Quantization Cuda vs Triton - 知乎
Deciphering LLMs: From Transformers to Quantization
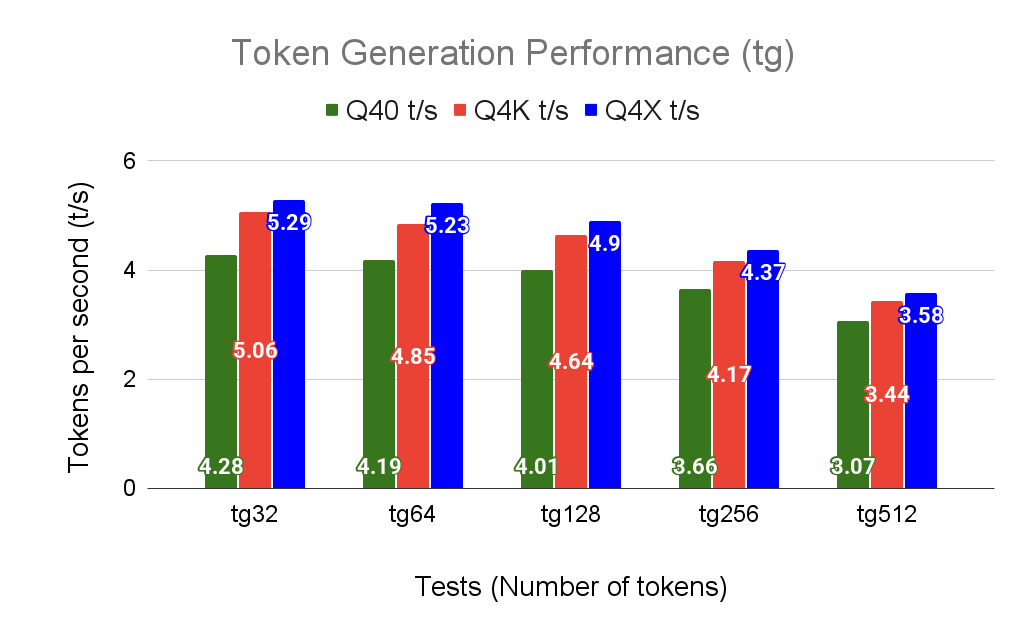
LLM Inference with Codebook-based Q4X Quantization using the Llama.cpp ...
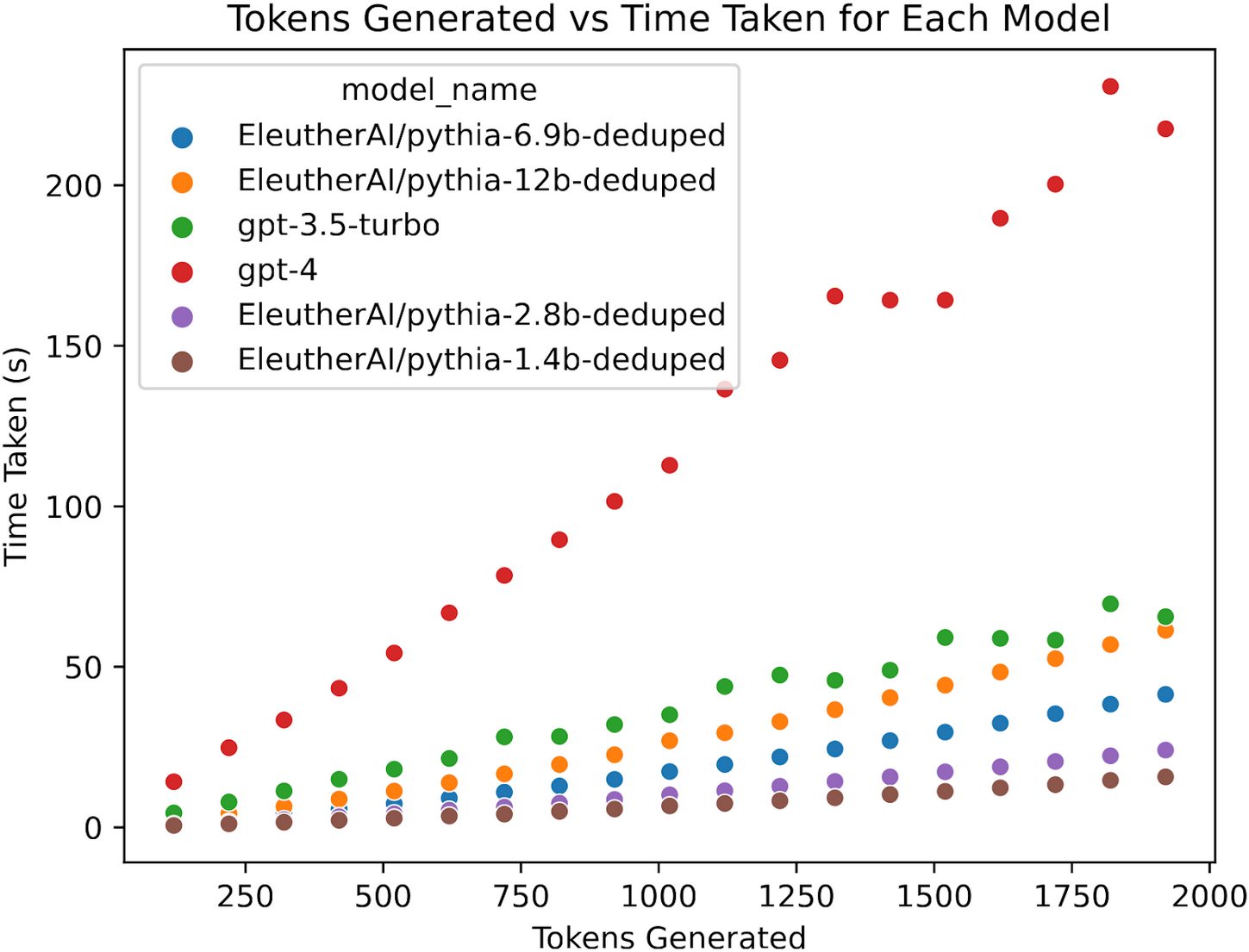
LLM Token Economics: Why AI Models Are Getting Cheaper
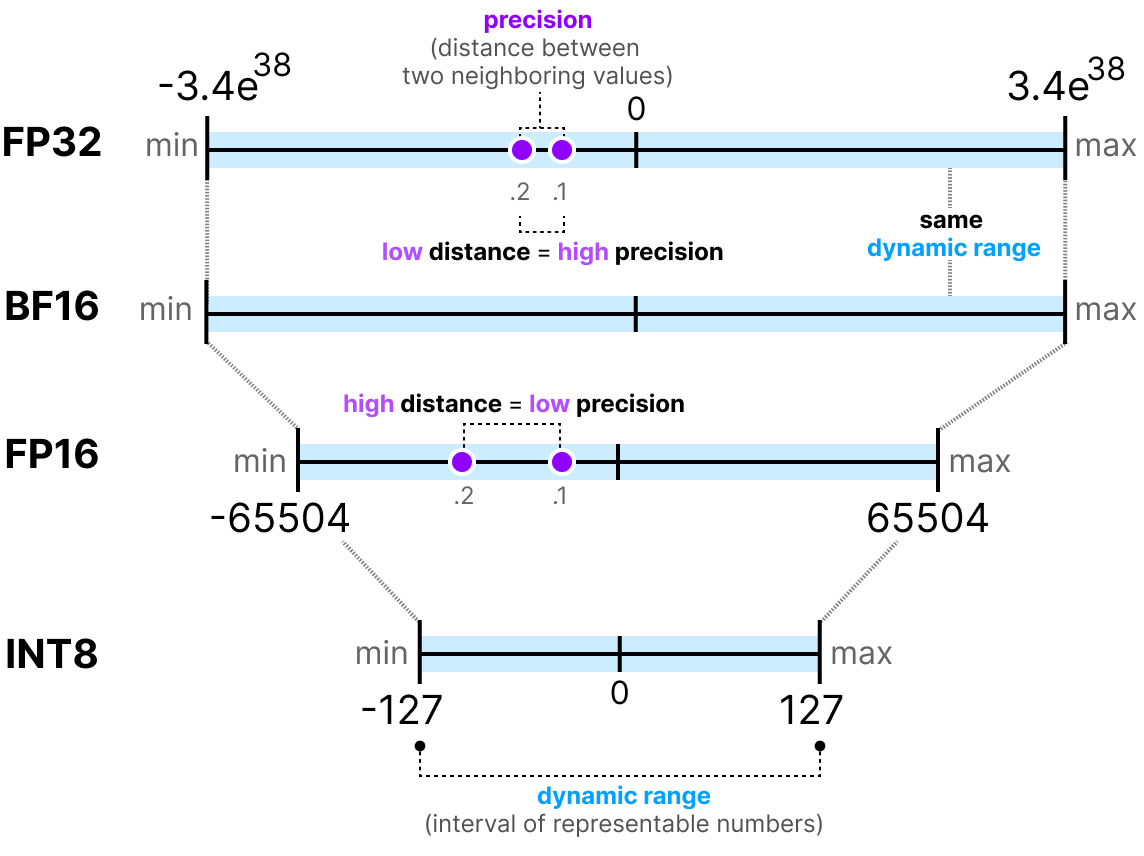
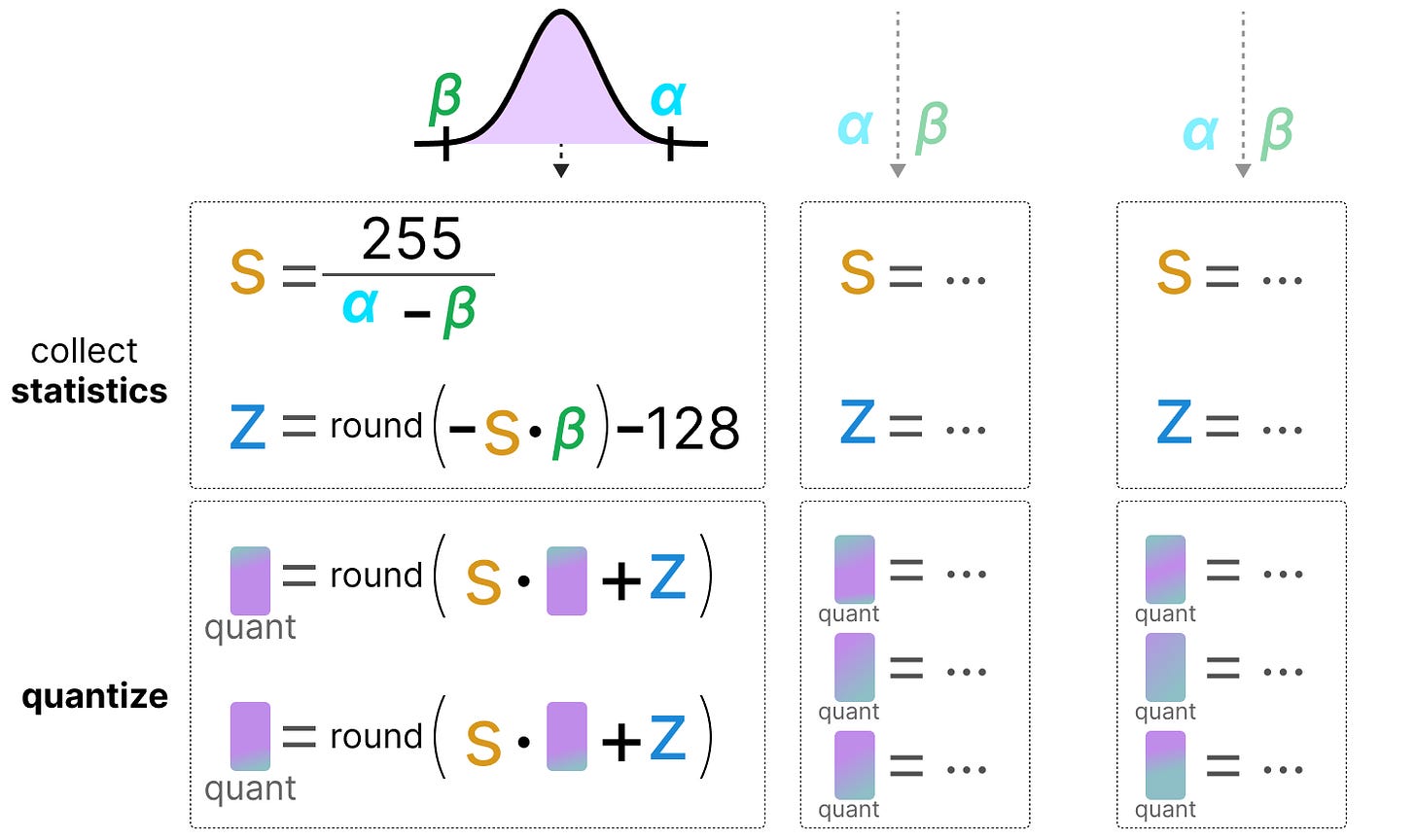
A Visual Guide to Quantization - by Maarten Grootendorst
Paper review[LLM-QAT: Data-Free Quantization Aware Training for Large ...
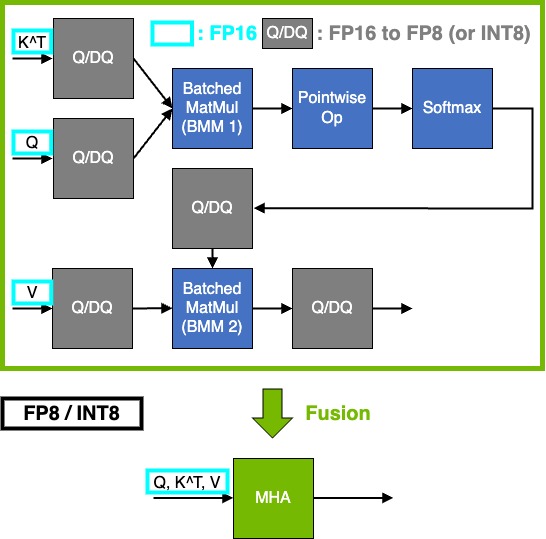
Fast and Accurate GPU Quantization for Transformers | Speechmatics
is fp8 quantization with block-wise/per-token/per-channel supported ...
Quantization Overview — Guide to Core ML Tools
[2305.17888] LLM-QAT: Data-Free Quantization Aware Training for Large ...
How to optimize large deep learning models using quantization
[Paper review] Trained quantization thresholds for accurate and ...
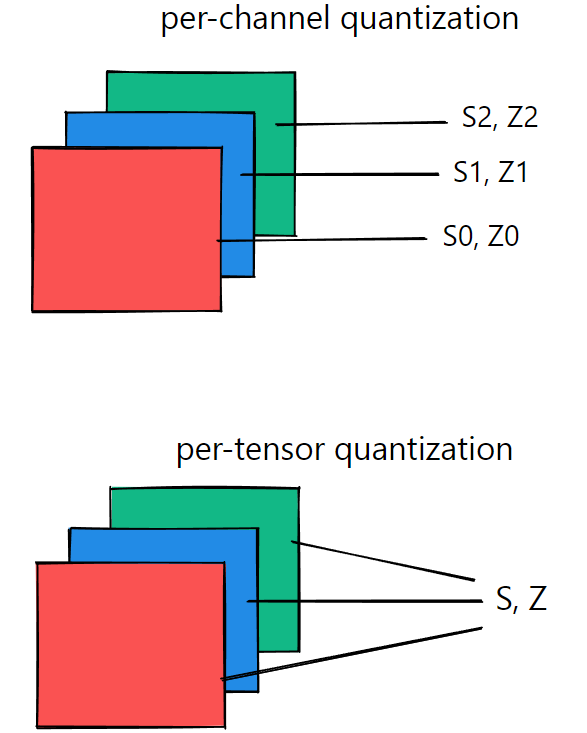
Per Channel Quantization. Table of Contents: | by Malpureomkar | Medium
Quantized Token Prediction Part of SC VALL-E. The style network on the ...
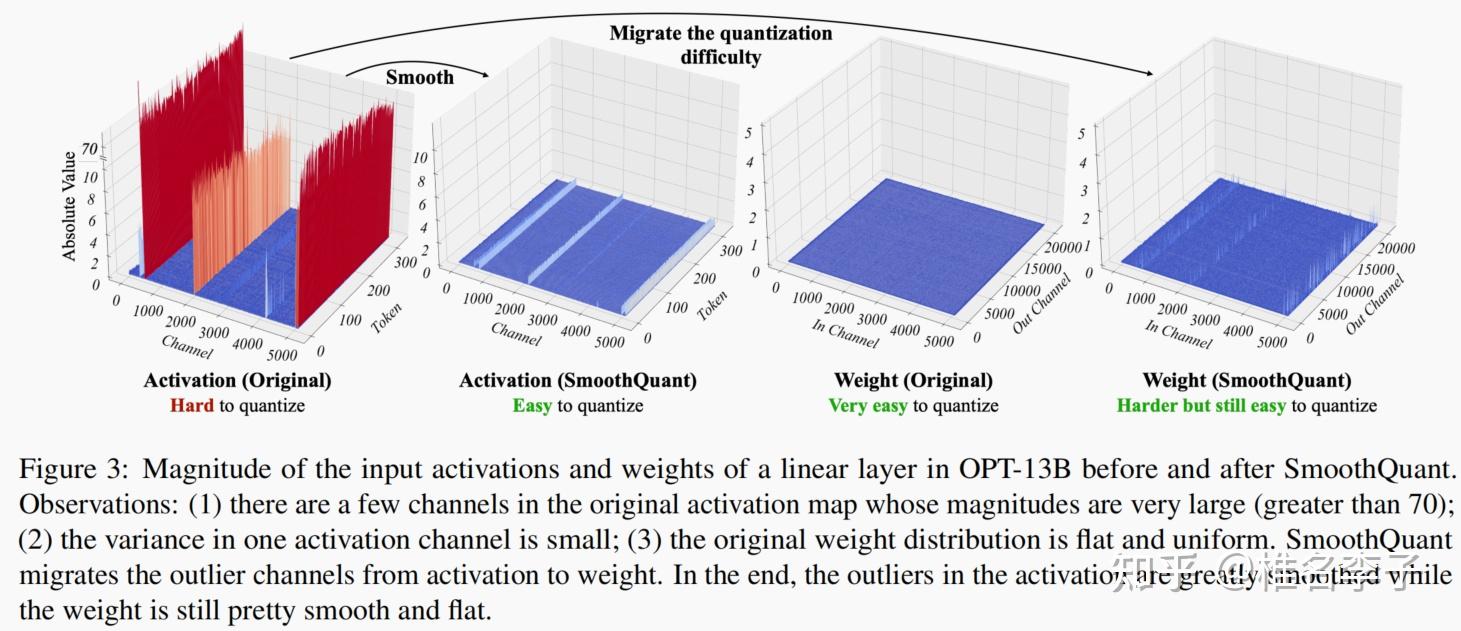
[LLM] SmoothQuant: Accurate and Efficient Post-Training Quantization ...
[2304.09145] Outlier Suppression+: Accurate quantization of large ...
阅读《KIVI: A Tuning-Free Asymmetric 2bit Quantization for KV Cache》 - 知乎
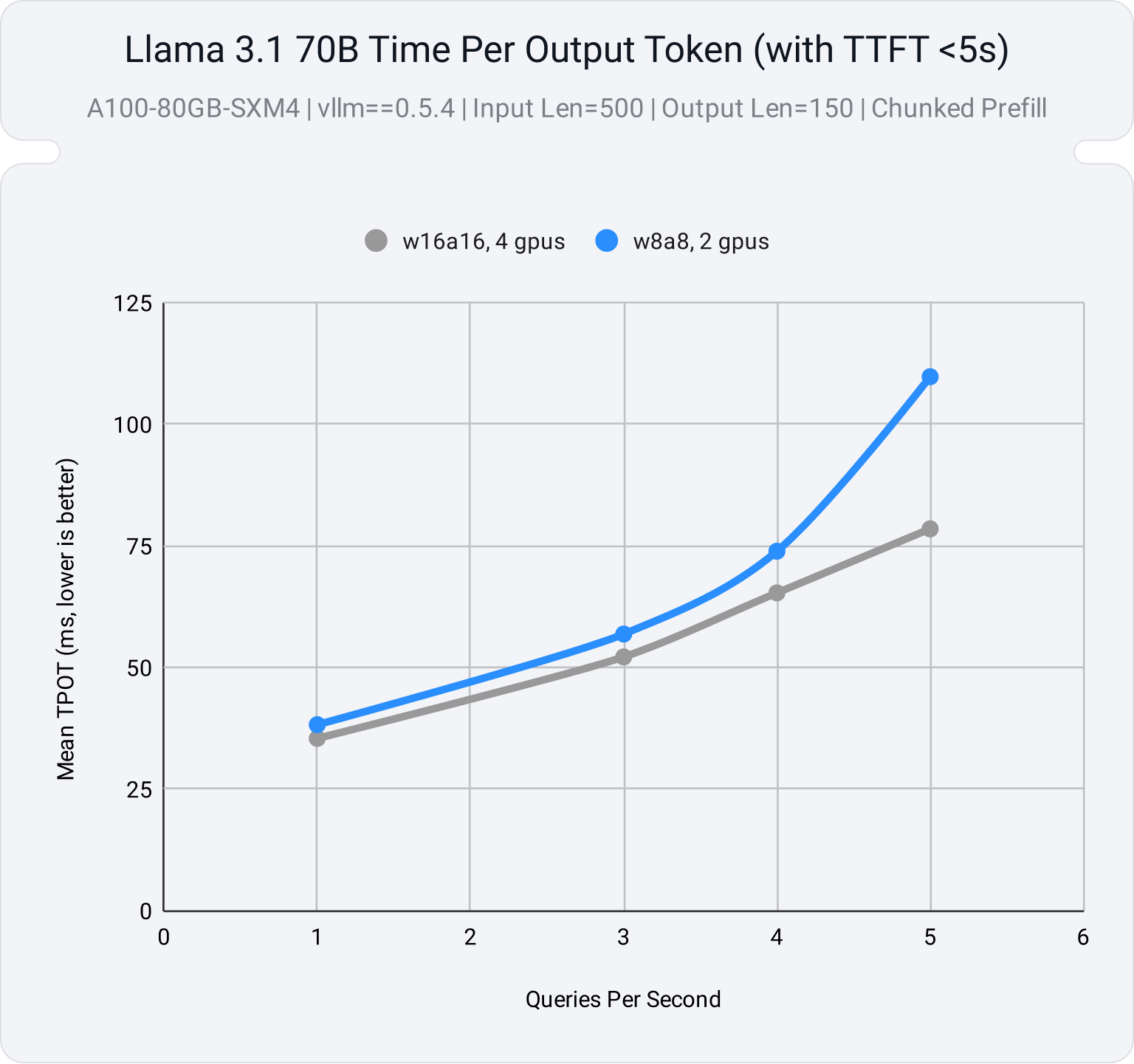
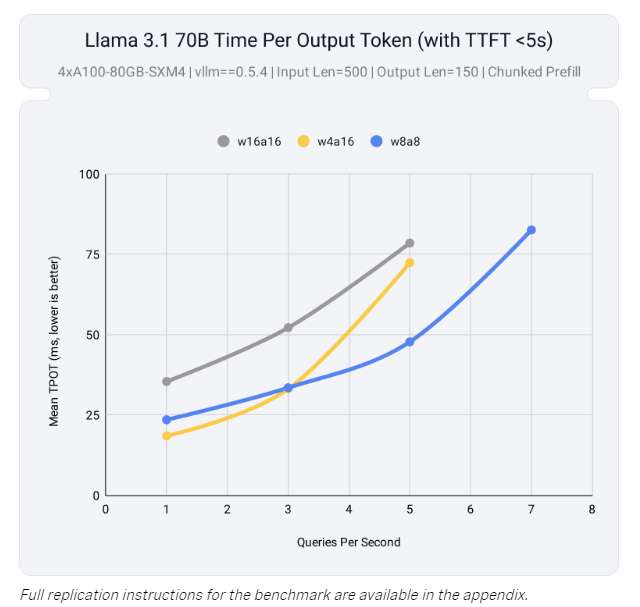
The Complete Guide to LLM Quantization with vLLM: Benchmarks & Best ...
Quantization for Neural Networks | Yang Yang
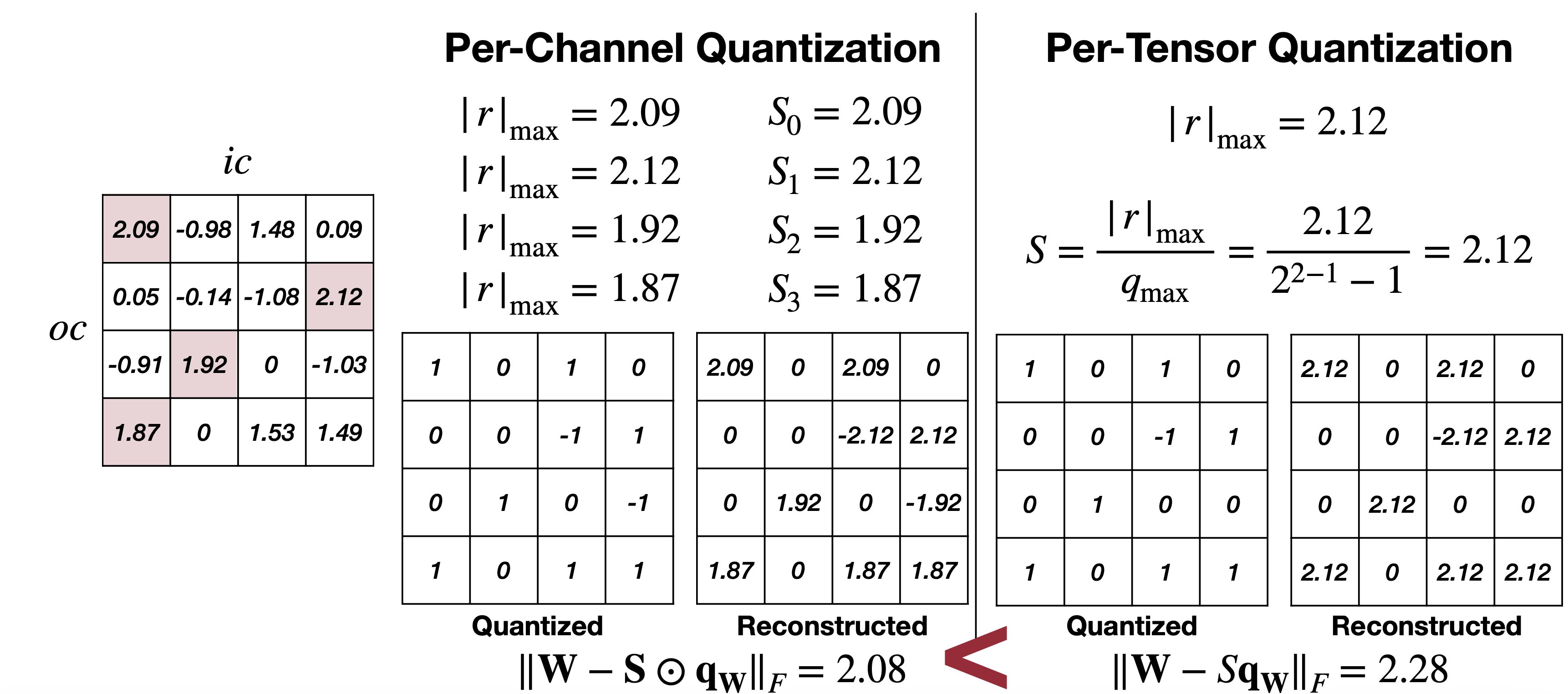
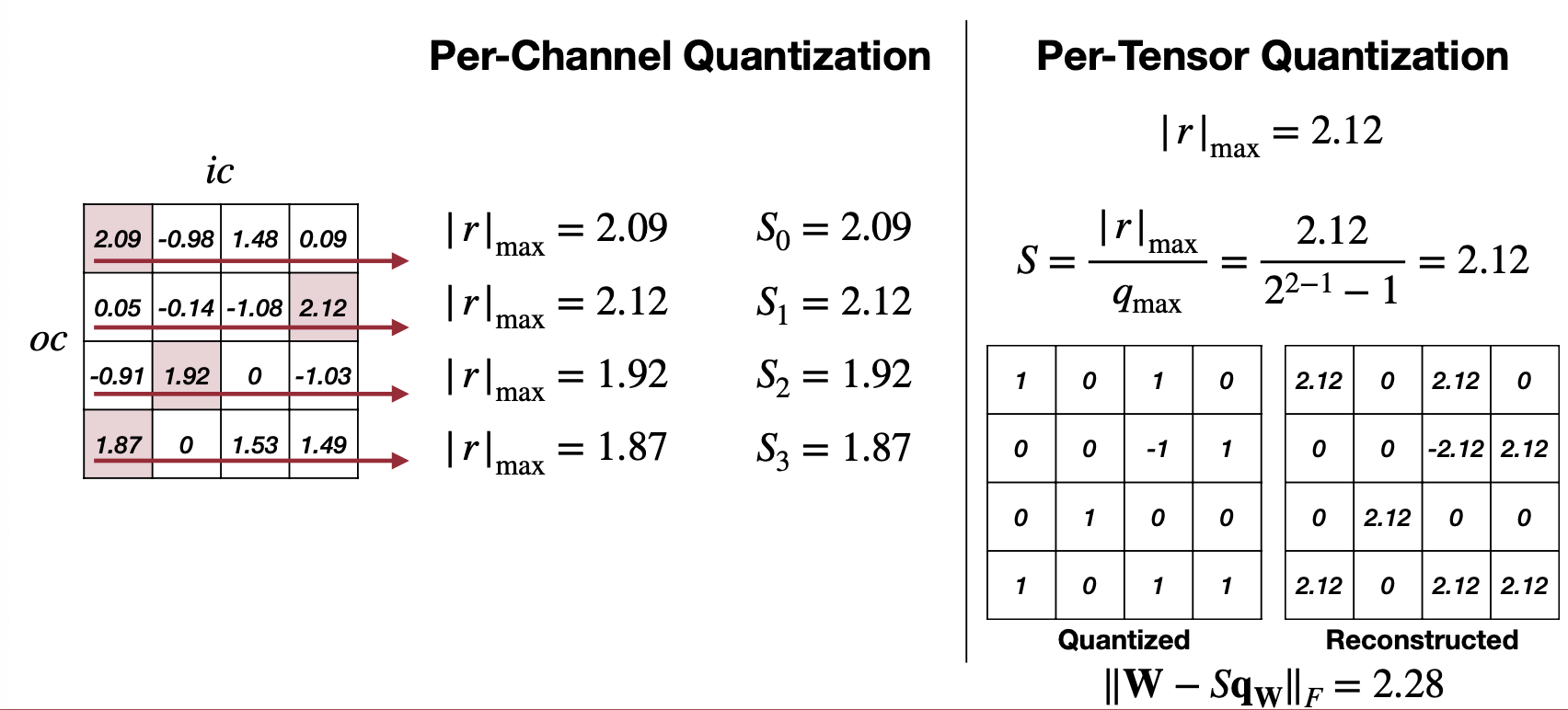
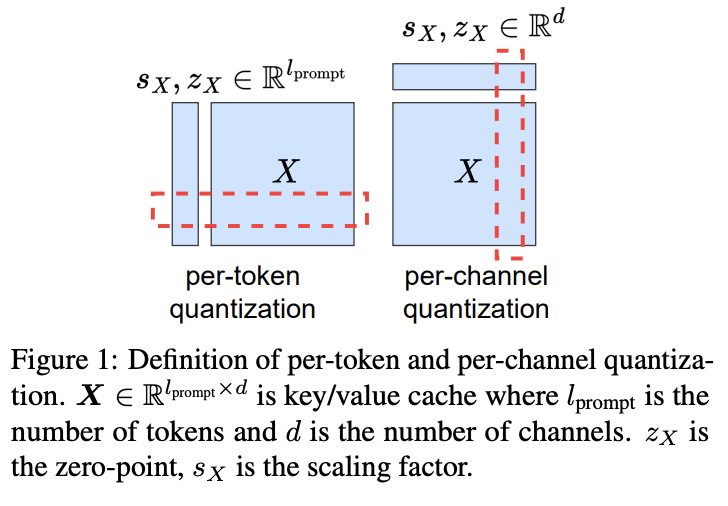
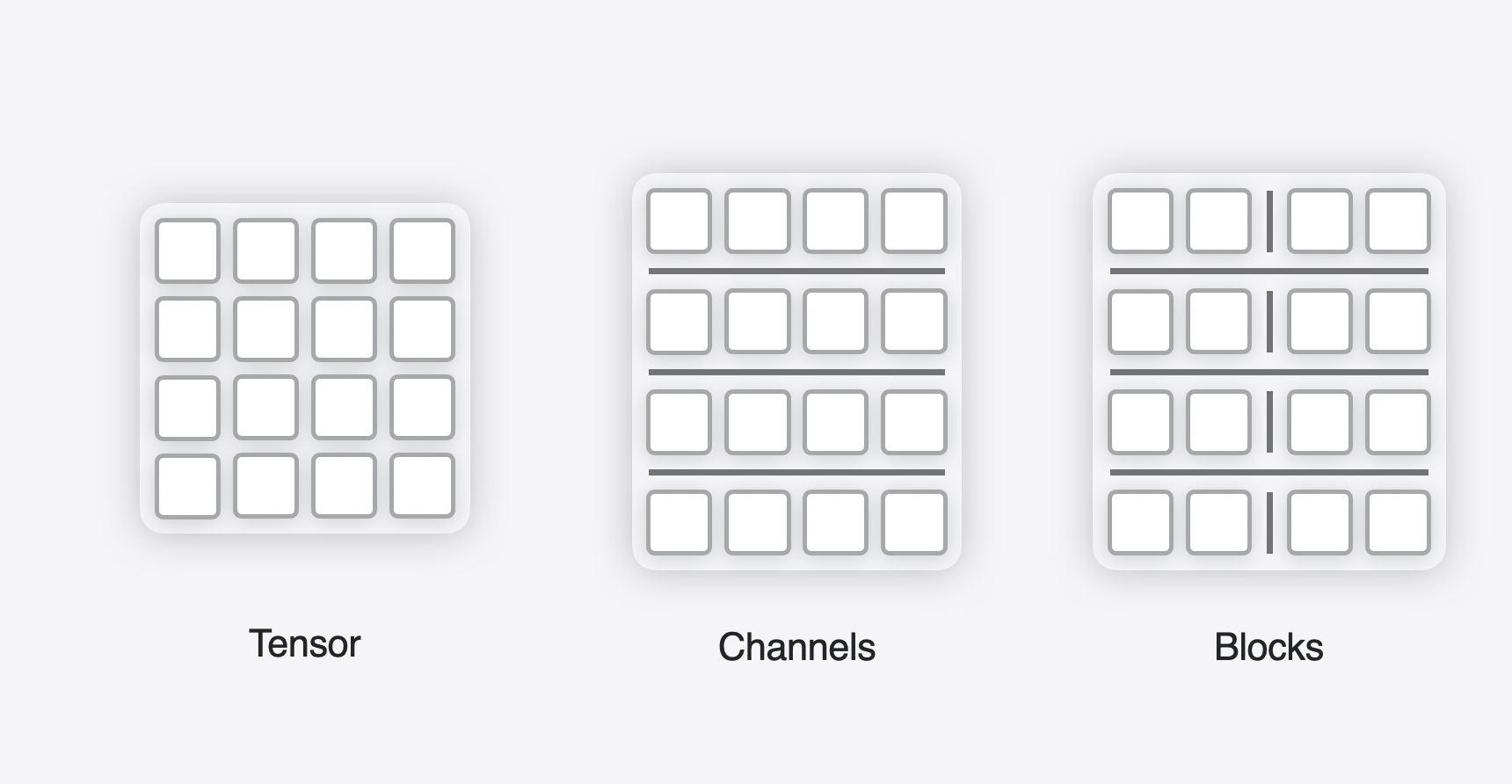
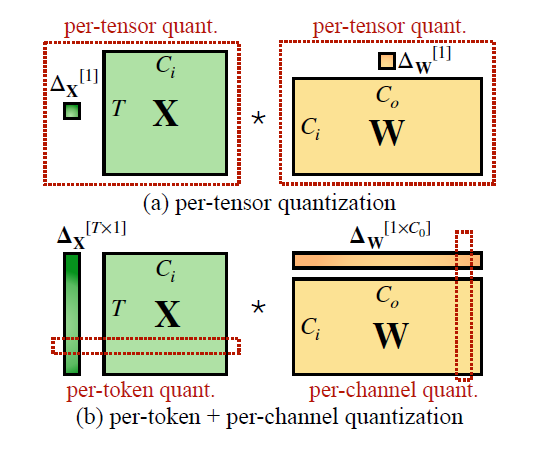
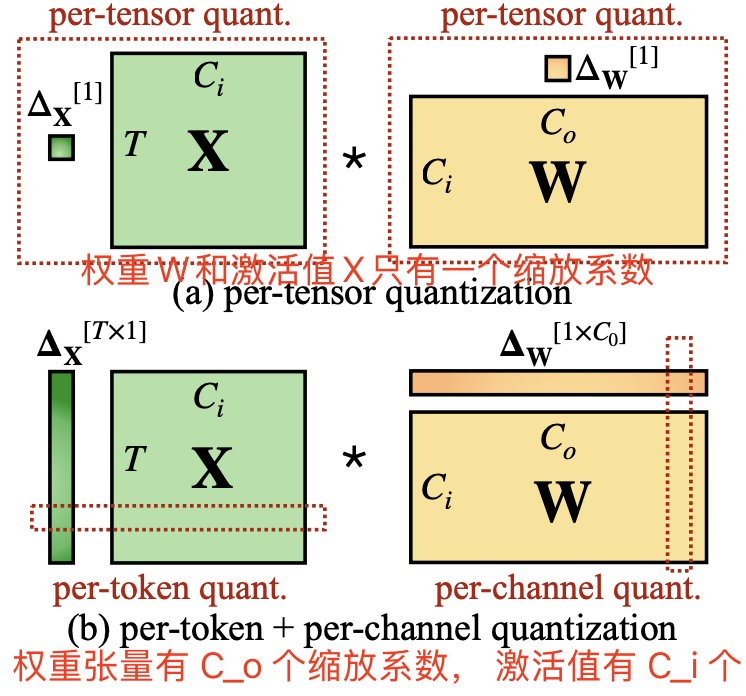
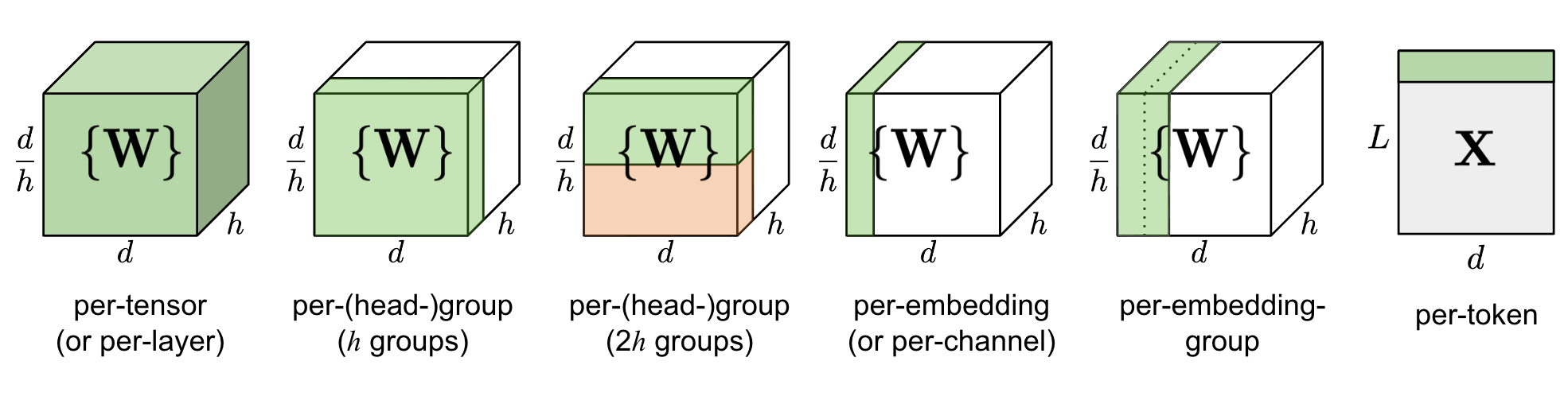
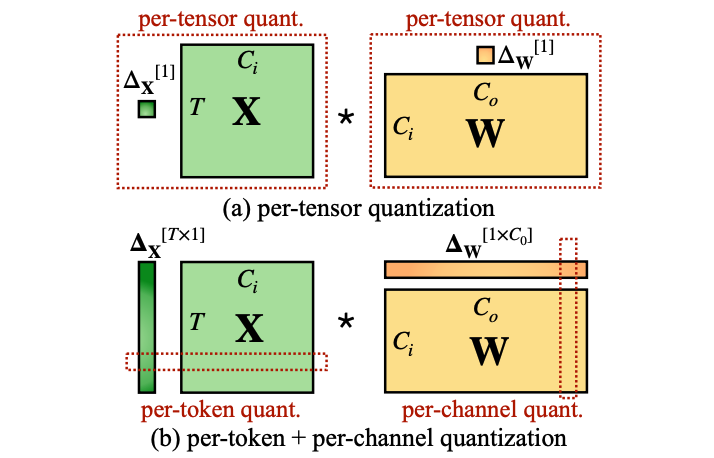
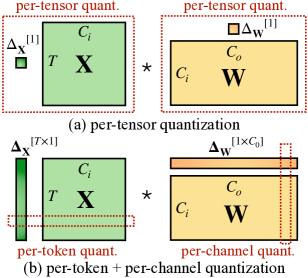
Per-Tensor, Per-Channel, Per-Group Quantization
Accurate KV Cache Quantization with Outlier Tokens Tracing - YouTube
FP8 quantization with AMD Quark for vLLM — Tutorials for AI developers 5.0
A Visual Guide to Quantization - Maarten Grootendorst
Optimizing Neural Networks: Unveiling the Power of Quantization
Perplexity API Pricing (Updated 2026) – All Models & Token Costs
🧠 Quantization Explained with PyTorch: Smarter, Smaller, and Faster AI ...
Understanding Activation-Aware Weight Quantization (AWQ): Boosting ...
Quick Guide To Quantization In Machine Learning
Approach overview. (a) A 1D CNN based latent quantization model is ...
Advanced Quantization Techniques for Large Language Models in 2026 | PDF
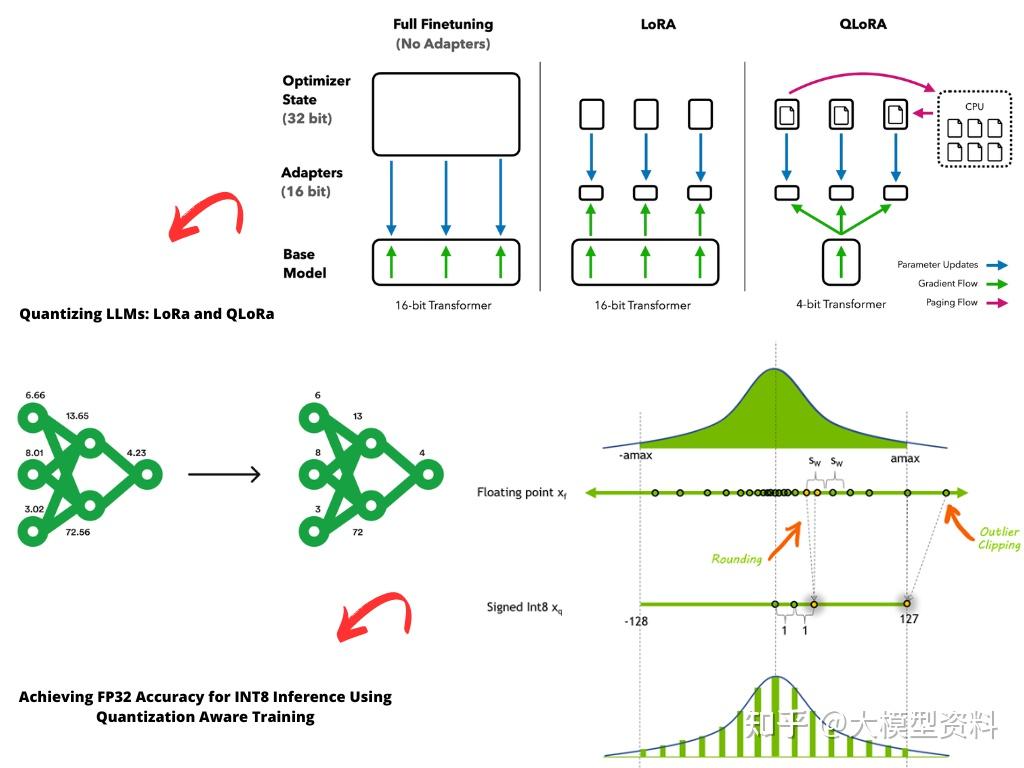
Mastering QLoRa : A Deep Dive into 4-Bit Quantization and LoRa ...
[21.06] A White Paper on Neural Network Quantization
VQ-Seg: Vector-Quantized Token Perturbation for Semi-Supervised Medical ...
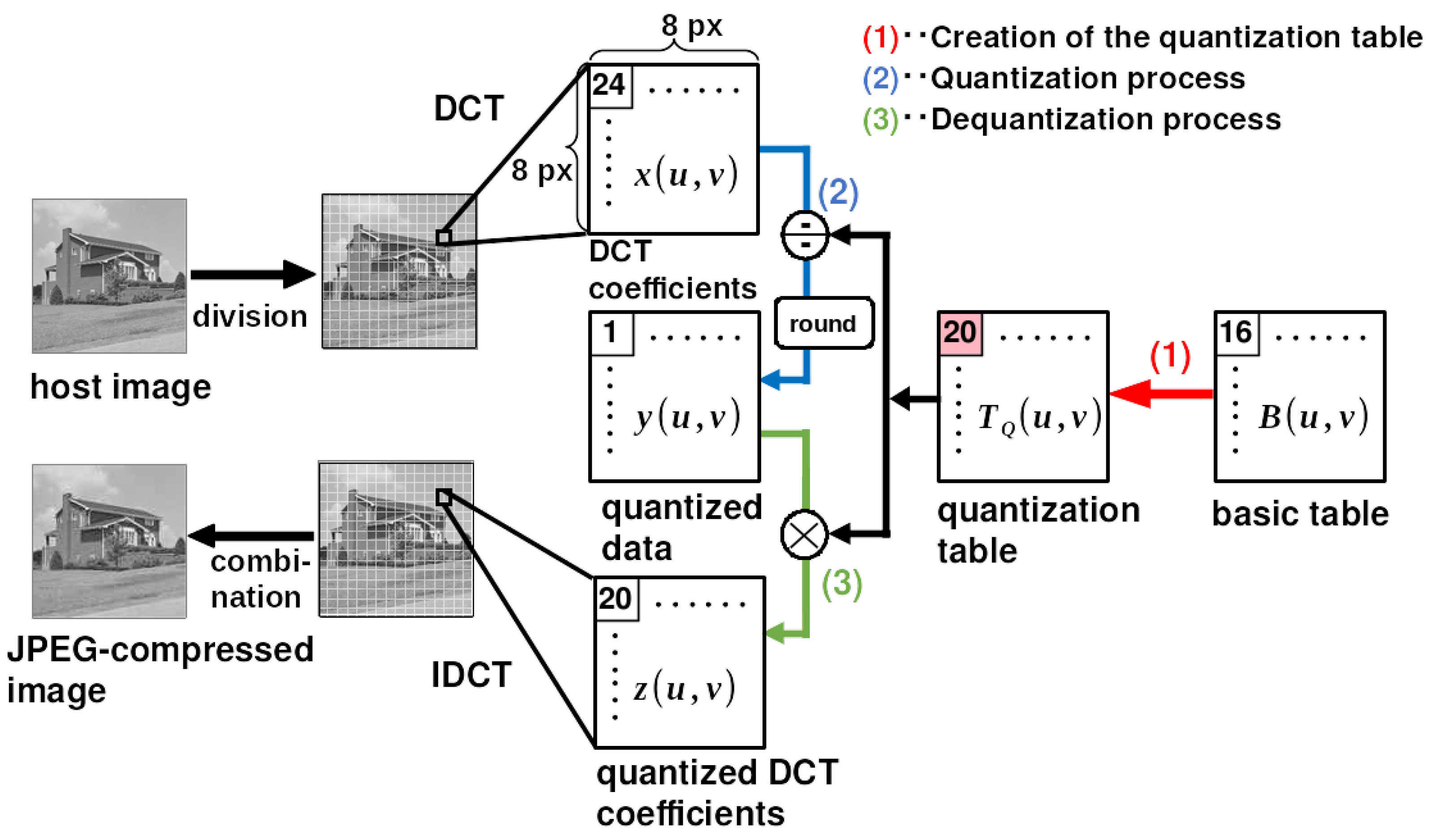
A Neural-Network-Based Watermarking Method Approximating JPEG Quantization
Top LLM Quantization Methods and Their Impact on Model Quality
Quantization in the context of deep learning and neural networks
Integer quantization for deep learning inference: principles and ...
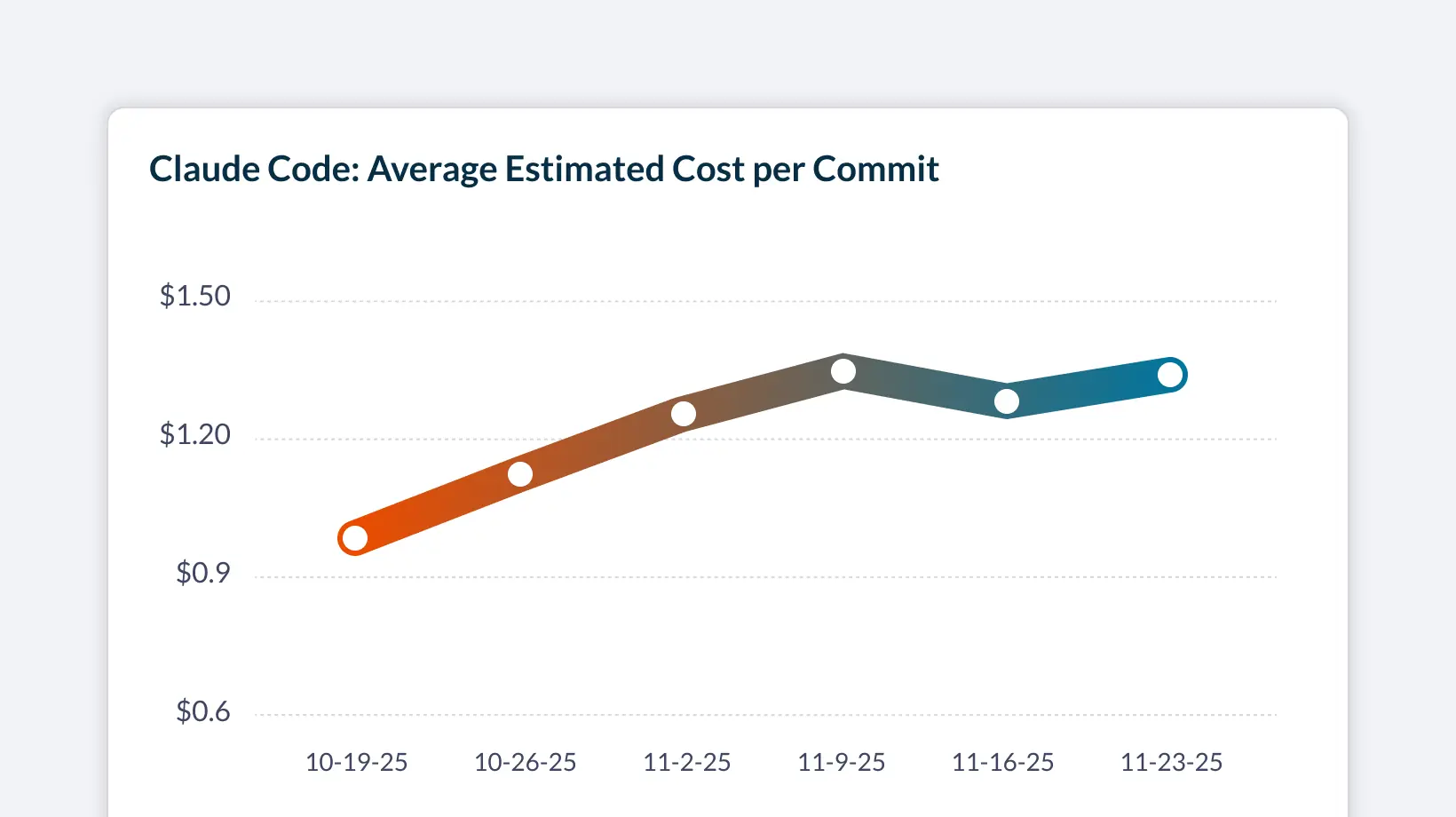
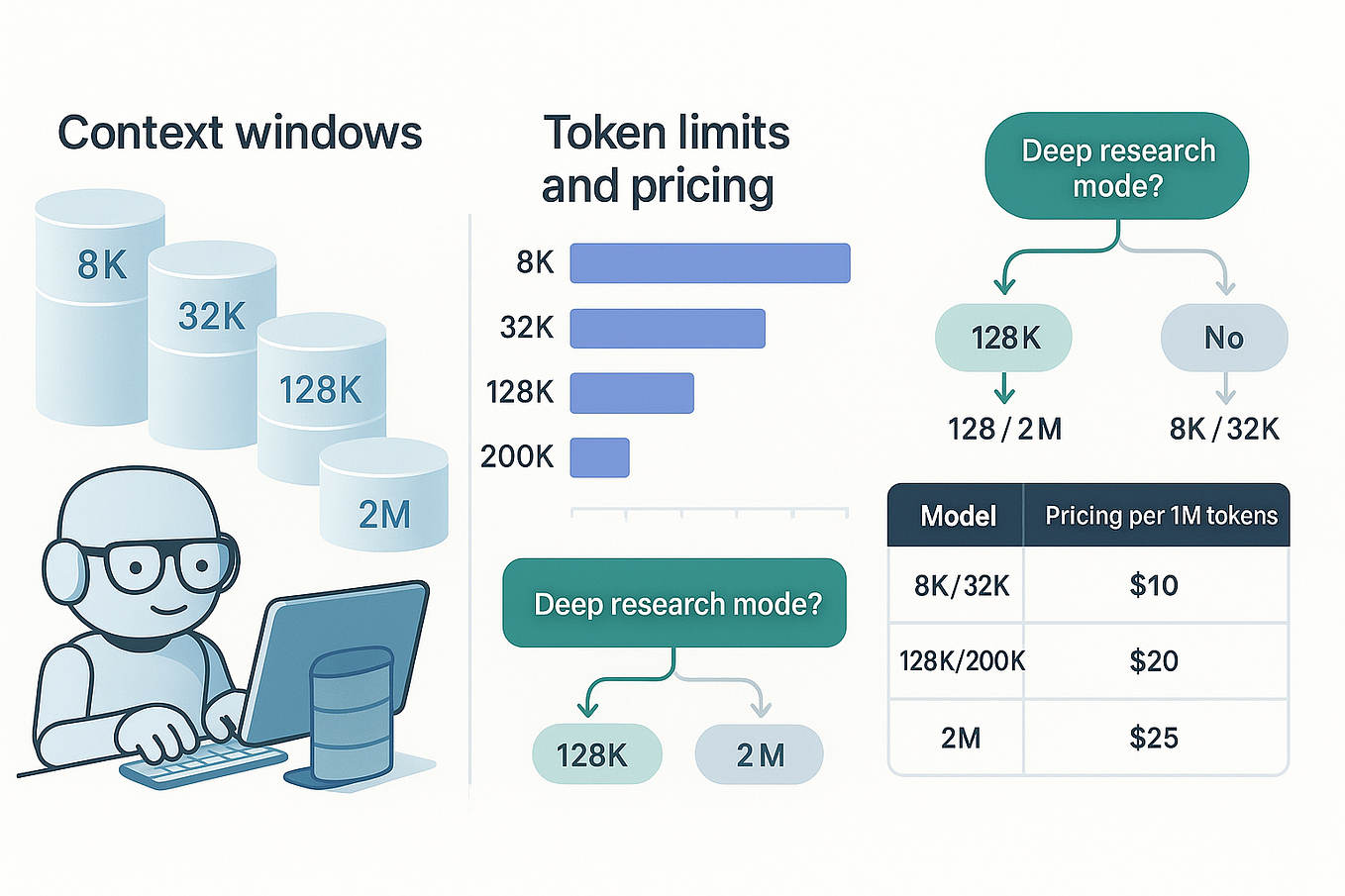
Claude Code Token Limits: A Guide for Engineering Leaders | Faros AI
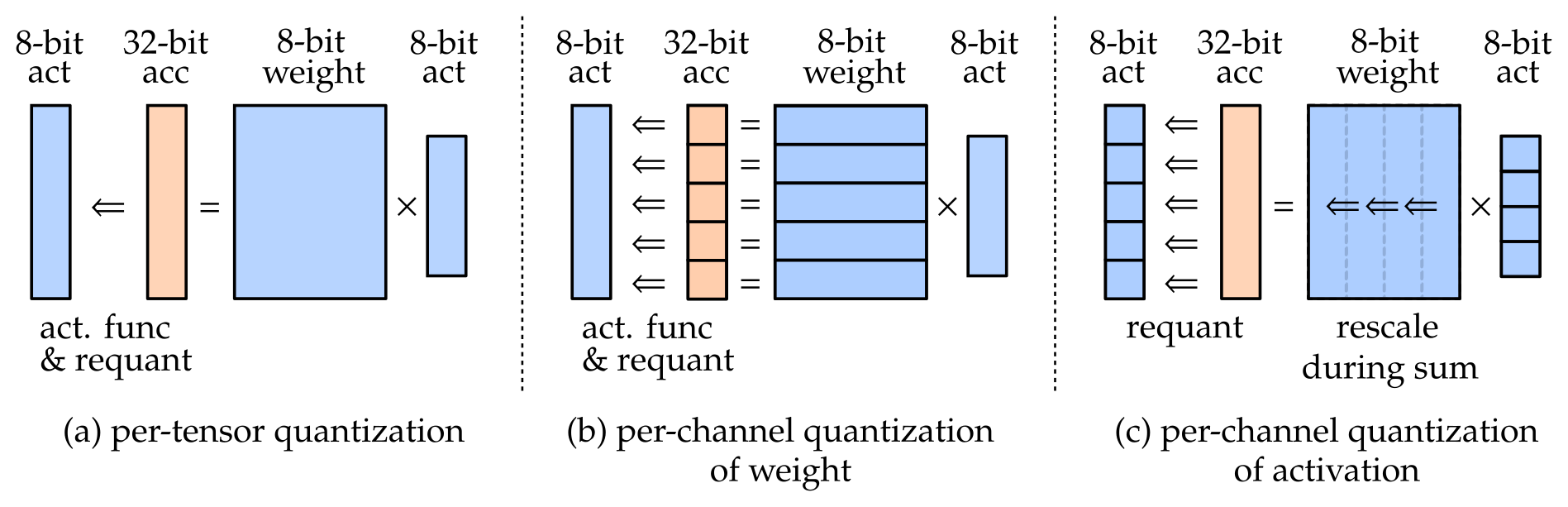
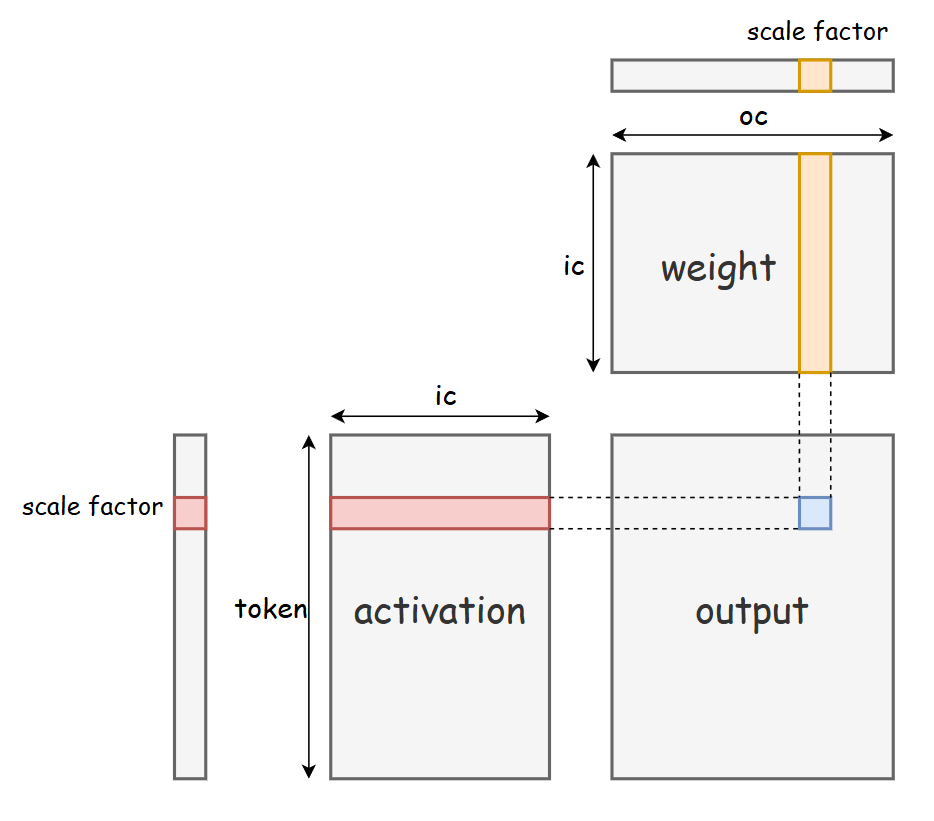
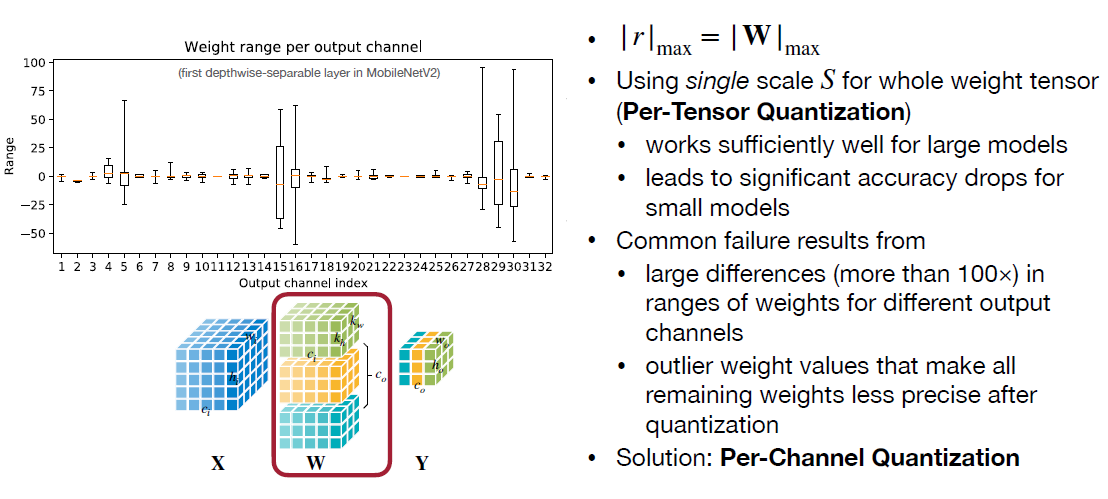
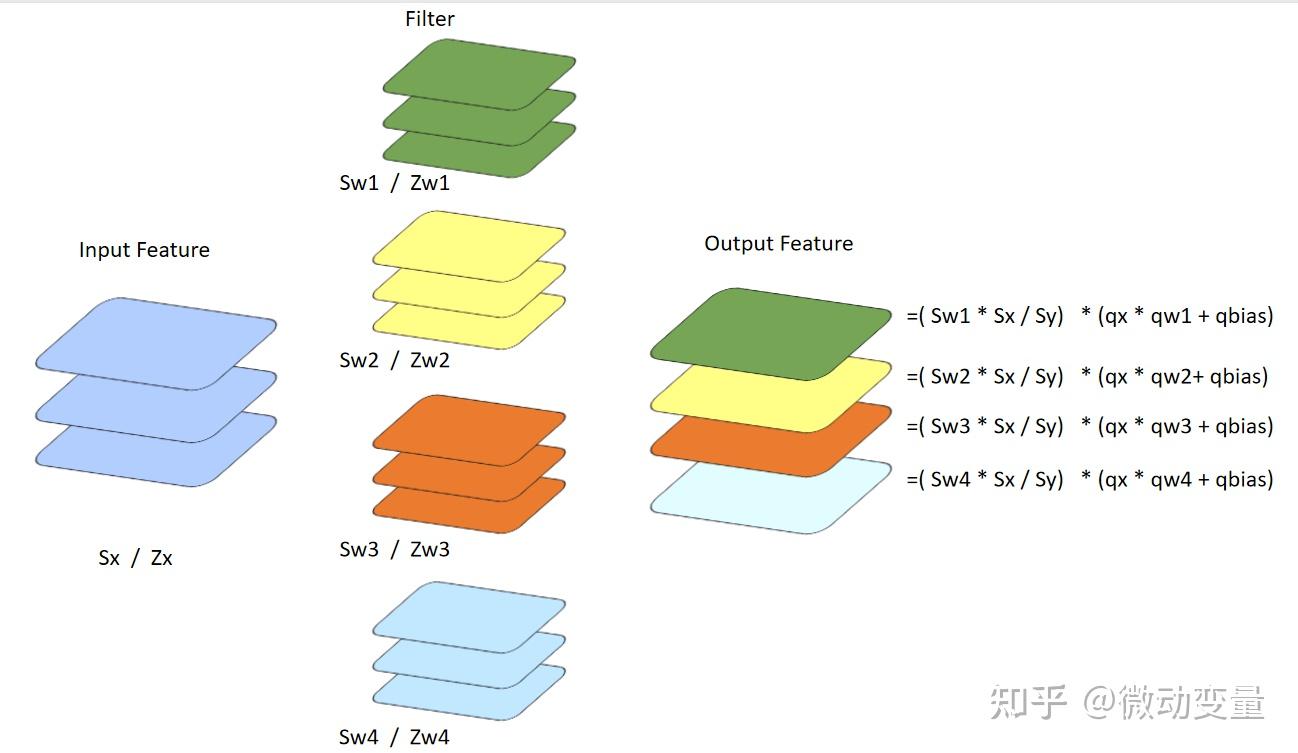
Optimizing Per-Channel Quantization for Improved Inference Performance ...
Overview of natively supported quantization schemes in 🤗 Transformers
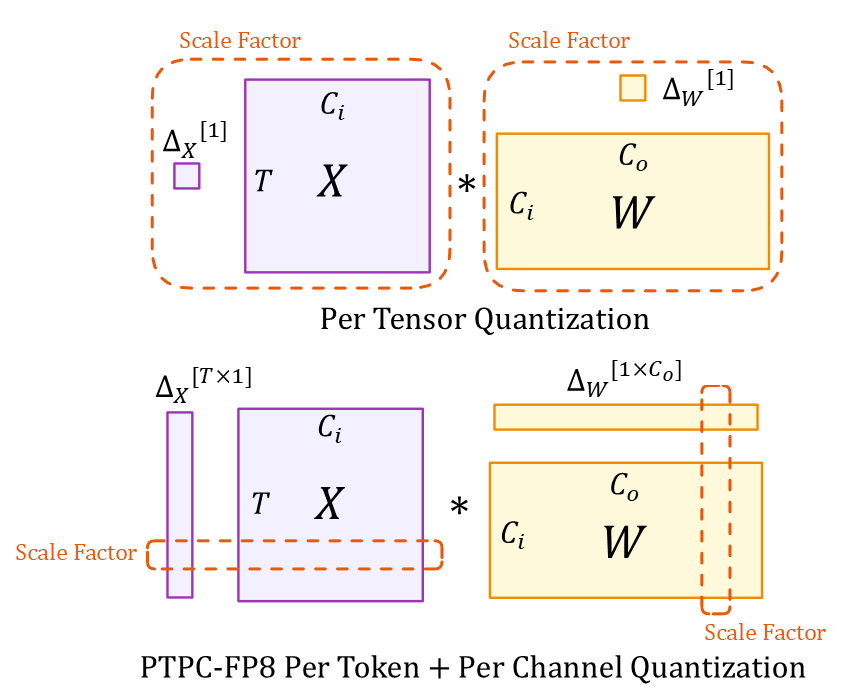
PTPC-FP8:提升 AMD ROCm 上的 vLLM 性能 | vLLM 博客
LLM 量化技术小结 - 知乎
SmoothQuant 量化详解 - Zhang
LLM Compressor is here: Faster inference with vLLM | Red Hat Developer
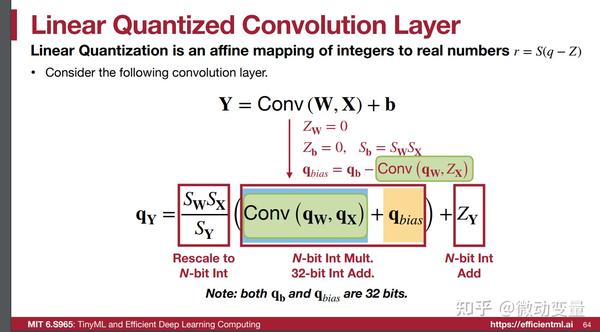
MIT-TinyML学习笔记【5】Quantization2 - 知乎
Unleashing Computational Power: Ultimate Latency Optimization of Qwen3 ...
模型量化原理与实践 – Robot 9
notion image
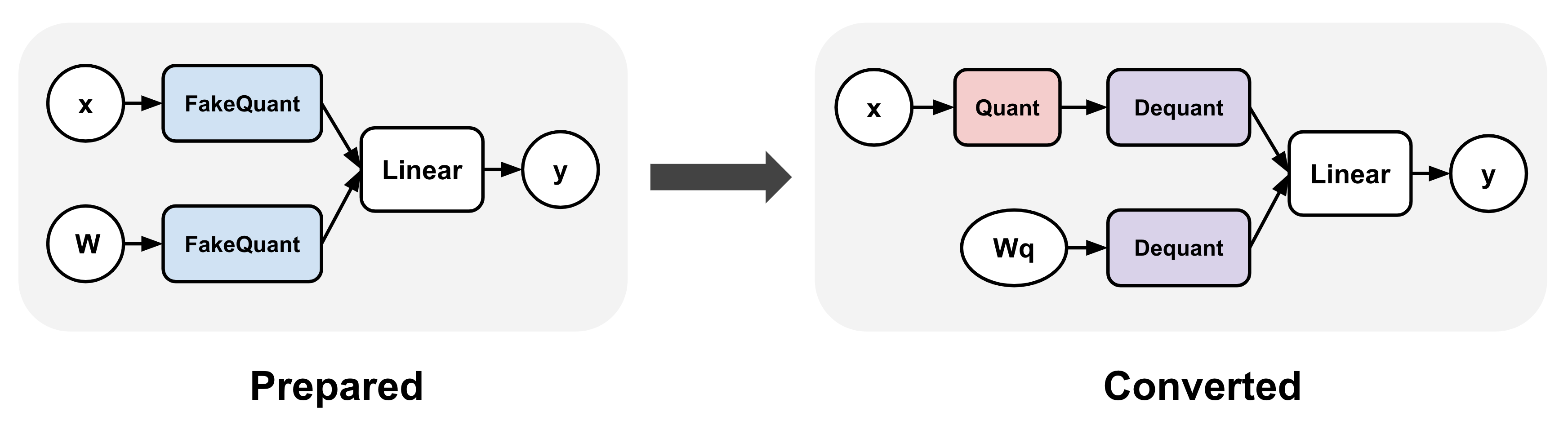
Quantization-Aware Training for Large Language Models with PyTorch ...
Understanding QLoRA | Di's Blog
[2211.10438] SmoothQuant: Accurate and Efficient Post-Training ...
[2310.09259] 1 Introduction
隆重推出 NVFP4,实现高效准确的低精度推理 - NVIDIA 技术博客
Model Quantization: Run Large AI Models on Limited Hardware
模型量化-llm量化 - 知乎
ZeroQuant与SmoothQuant量化总结-CSDN博客
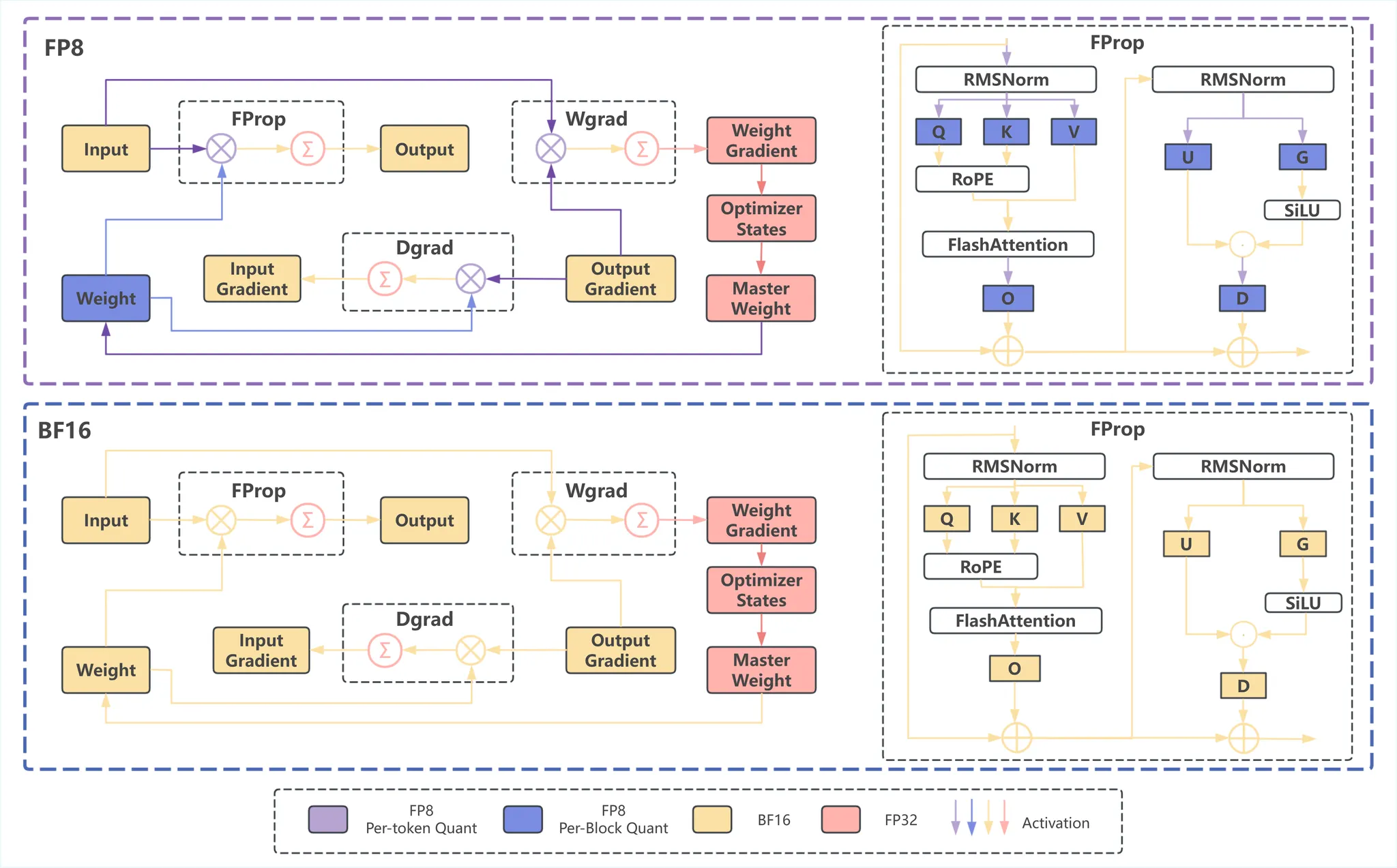
Unified FP8: Moving Beyond Mixed Precision for Stable and Accelerated ...
What will GPT-2030 look like?
大语言模型的模型量化(INT8/INT4)技术-CSDN博客
MIT 6.5940(一)-CSDN博客
Serving Quantized LLMs on NVIDIA H100 Tensor Core GPUs | Databricks
All you need to know about Tokenization in LLMs | by Tayyib Ul Hassan ...
Overview of two-stage quantization. It is composed of a clustering ...
Paper review[KV Quant: Towards 10 Million Context Length LLM Inference ...
Optimizing LLMs for Performance and Accuracy with Post-training ...
Neural Magic Releases LLM Compressor: A Novel Library to Compress LLMs ...
四. TensorRT模型部署优化-quantization(quantization granularity)_tensorrt ...
MIT-TinyML学习笔记【5】Quantization2_tinyml 训练-CSDN博客
The per-token distribution of the deviation (ε) of information content ...
SmoothQuant論文まとめ
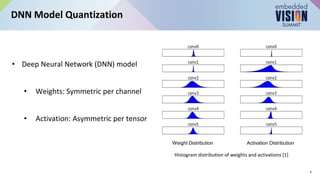
“DNN Quantization: Theory to Practice,” a Presentation from AMD | PDF
Inside the NVIDIA Vera Rubin Platform: Six New Chips, One AI ...
大模型入门指南 - Quantization:小白也能看懂的“模型量化”全解析 - 知乎
NVIDIA Accelerates Inference on Meta Llama 4 Scout and Maverick ...
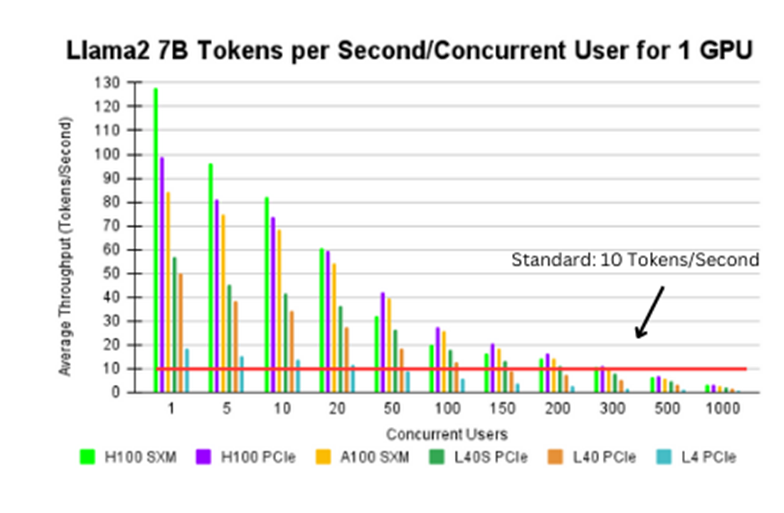
Benchmarking NVIDIA GPU Throughput for LLMs and Understanding GPU ...
目前针对大模型进行量化的方法有哪些? - 知乎
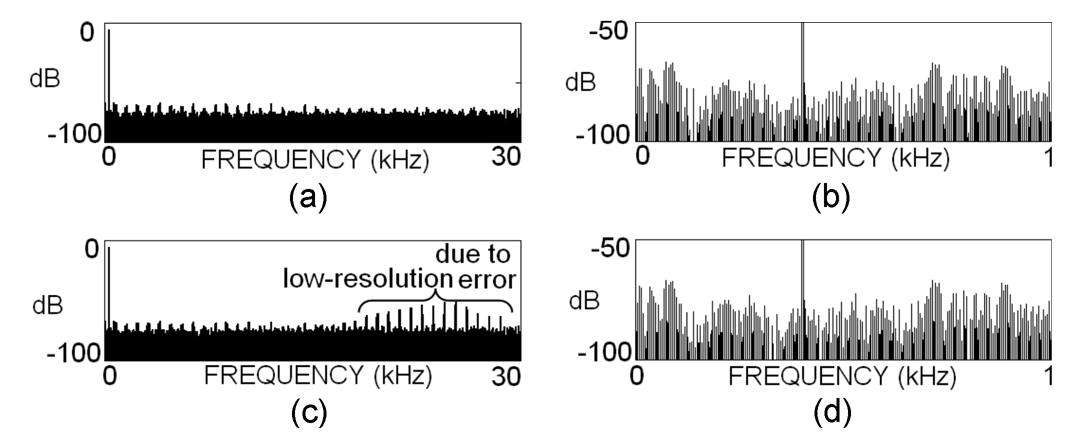
Spectrum of a quantized two-tone spectrum for the (a) and
Working with Transformers — NVIDIA TensorRT
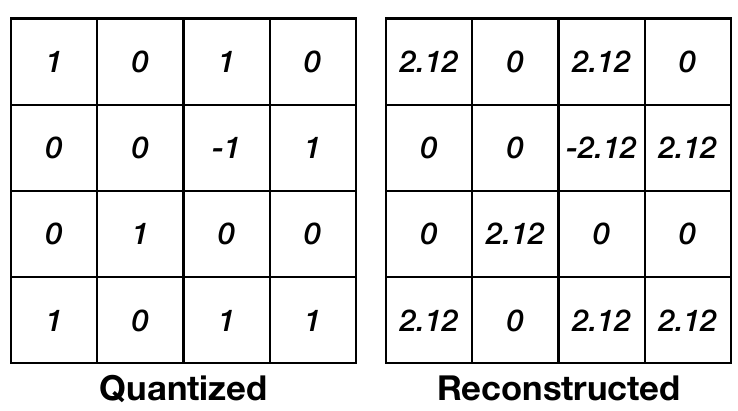
模型量化Quantization - 知乎
[24.arXiv]KVQuant: Towards 10M Context Length LLM Inference with KV ...
Quantization-Aware Training | AI Tutorial | Next Electronics
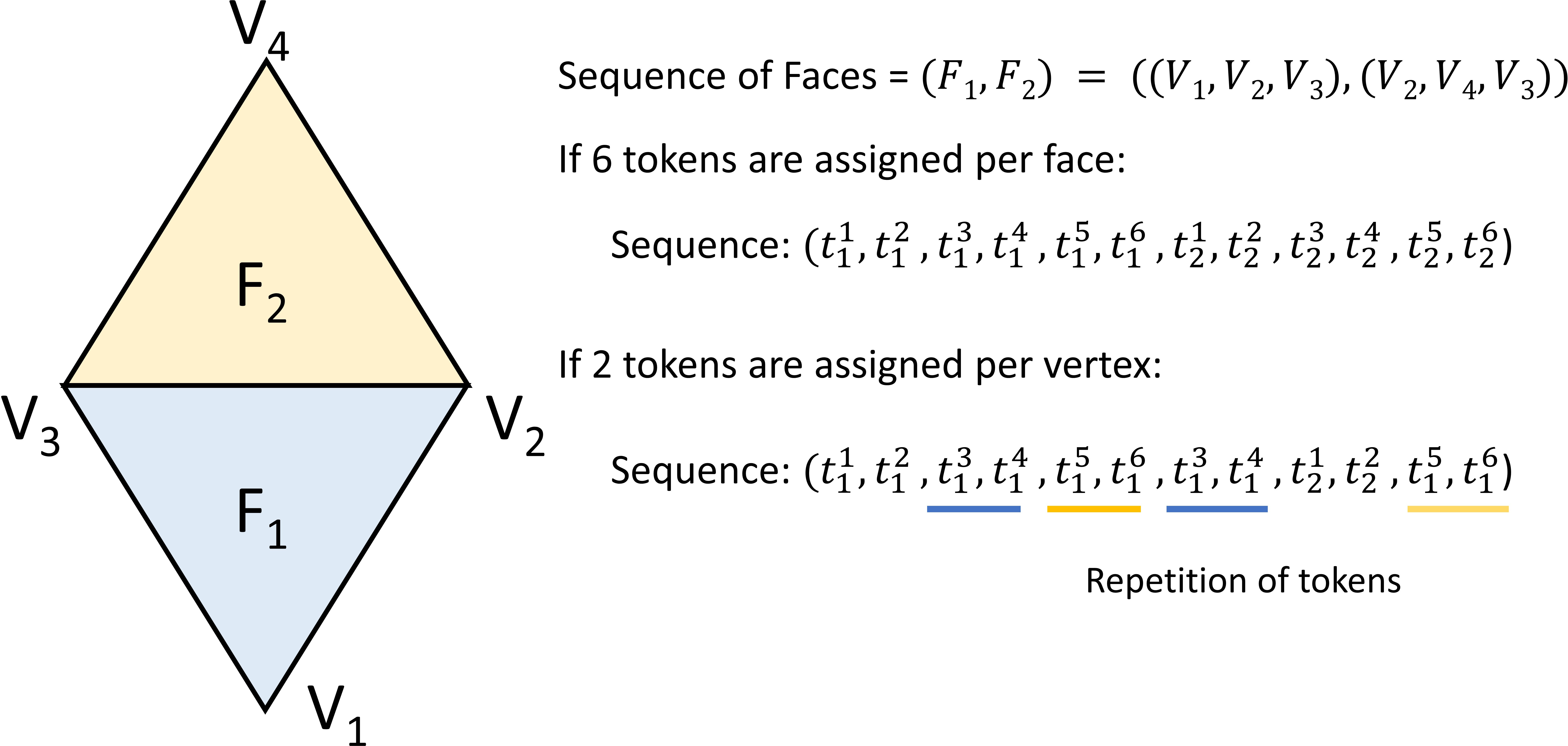
[2311.15475] MeshGPT: Generating Triangle Meshes with Decoder-Only ...
“Practical Approaches to DNN Quantization,” a Presentation from Magic ...
[Fundamental] 模型量化 | Ubios Home
Model Quantization: Concepts, Methods, and Why It Matters | NVIDIA ...
How to Quantize Neural Networks with TensorFlow « Pete Warden's blog
AI Tokens Explained: Complete Guide to Usage, Optimization & Costs
大模型推理的部署优化 - 知乎